

敵対的生成ネットワーク (GAN)
解説:「偽造犯」と「警察」のいたちごっこ
GAN(ガン:Generative Adversarial Network)は、2014年にイアン・グッドフェロー氏らによって考案された、「2つのニューラルネットワークを競わせてデータを生成する」画期的なモデルです。
教師あり学習のように「正解」を覚えるのではなく、以下の2者が「敵対的(Adversarial)」に学習を進めるのが最大の特徴です。
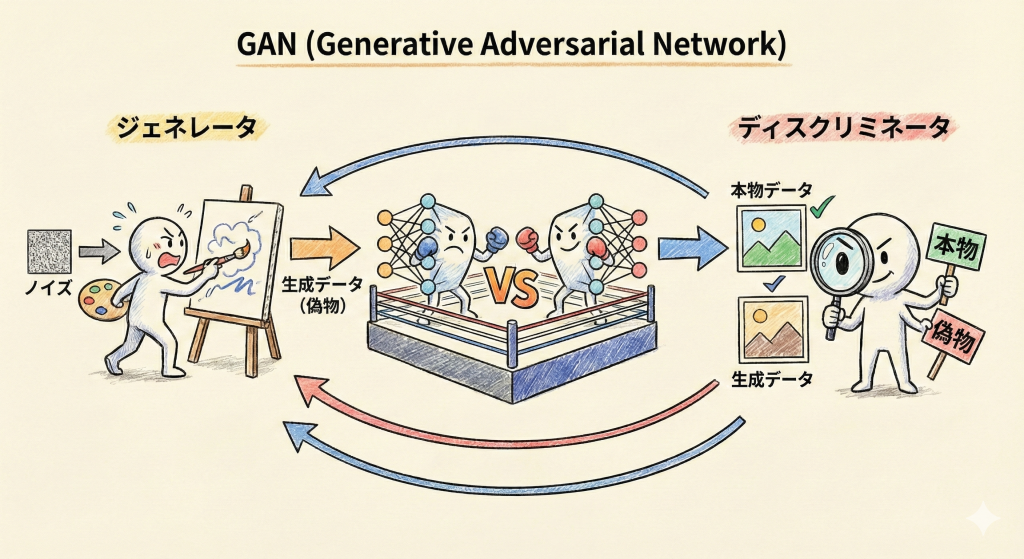
GANの仕組みは、よく「偽札を作る犯人」と「それを見破る警察」に例えられます。
- ジェネレータ(生成器):
警察を騙そうとして、ランダムなノイズから本物そっくりの偽札(偽画像)を作ります。 - ディスクリミネータ(識別器):
渡されたお札が「本物」か「ジェネレータが作った偽物」かを厳しく判定(識別)します。
最初は下手な偽札しか作れませんが、警察に見破られるたびに「次はもっとうまくやるぞ」と学習し、警察も「もっと厳しく見るぞ」と学習します。このいたちごっこ(ミニマックスゲーム)を繰り返すことで、最終的にプロの警察(人間)でも見分けがつかないほどの完璧な画像が生成されます。
試験に出る!主要な派生モデル詳細
GANは学習が不安定で難しいという欠点がありましたが、それを克服するために多くの改良版が登場しました。
1. DCGAN (Deep Convolutional GAN)
「GANにCNNを組み込んで安定させた」モデル。
初期のGANは全結合層を使っていましたが、これを画像処理が得意なCNN(畳み込みニューラルネットワーク)に置き換え、さらに「Batch Normalization」などの工夫を取り入れることで、学習を劇的に安定させました。現在の画像生成のベースとなっています。
2. cGAN (Conditional GAN)
「注文通りの絵を描ける」モデル。
通常のGANは何が出てくるか運任せ(ランダム)ですが、cGANは「犬の絵を出して」といったラベル(条件)を一緒に入力することで、意図した通りの画像を生成できます。
3. Pix2Pix
「ペア画像」で変換を学ぶモデル。
「線画と着色画像」「航空写真と地図」のように、1対1に対応するペア画像を用意して学習させます。入力画像の形を保ったまま、スタイルやテクスチャを変換するタスク(Image-to-Image translation)が得意です。
4. CycleGAN
「ペア画像なし」で変換できるモデル。
Pix2Pixの弱点(ペア画像の用意が大変)を克服したモデルです。「シマウマ」と「馬」のように、対応していないバラバラの画像群だけでスタイル変換が可能です。
「A→Bに変換して、またAに戻した時、元通りになっているべき(サイクル一貫性損失)」というルールを導入したのが画期的でした。
5. StyleGAN
「超高画質」な生成を実現したモデル。
NVIDIAが開発。以前のモデルとは桁違いに高精細な顔画像などを生成できます。画像の特徴を「髪型」「肌の色」などの階層(スタイル)に分けて調整できるのが特徴です。
G検定対策
比較まとめ表
| 名称 | キーワード | データの要件 |
|---|---|---|
| DCGAN | CNN、Batch Normalization | 画像のみ |
| Pix2Pix | スタイル変換 | ペア画像が必要 (線画⇔カラーなど) |
| CycleGAN | サイクル一貫性損失 (Cycle Consistency Loss) |
ペア画像は不要 (馬の群れ⇔シマウマの群れ) |
出題ポイント
- 学習原理:GeneratorとDiscriminatorによる「ミニマックスゲーム」。
- 入力:Generatorの入力は「ランダムノイズ」である。(※cGANの場合は+ラベル情報)
- CycleGAN:「元に戻して一致するか」を確認する「サイクル一貫性損失(Cycle Consistency Loss)」という用語が頻出です。
ひっかけ対策
- × Generatorは本物のデータを直接見て学習する
(解説)Generatorは本物を見れません。Discriminatorの判定結果(勾配情報)だけを頼りに学習します。 - × Pix2Pixはペア画像が不要である
(解説)ペアが不要なのは「CycleGAN」です。ここの入れ替え問題に注意しましょう。


📚 より詳細を学びたい方へ

