

セマンティックセグメンテーション (Semantic Segmentation)
解説:AIによる「デジタル塗り絵」
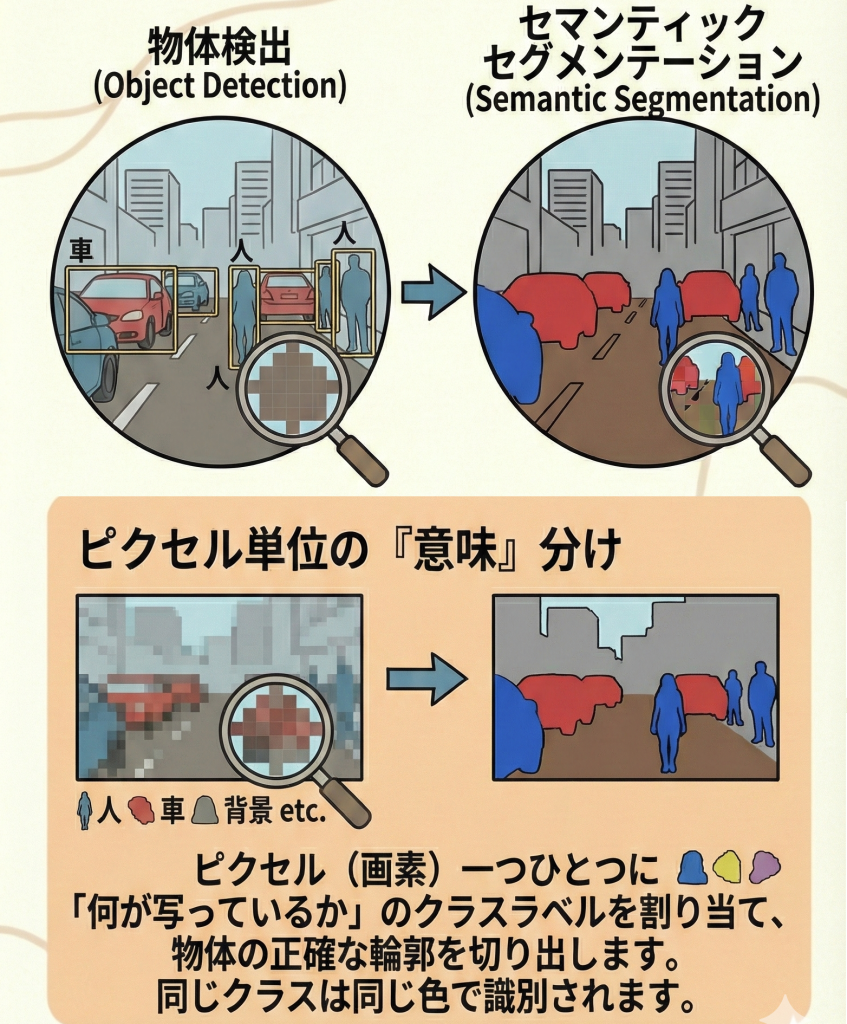
セマンティックセグメンテーション(意味的領域分割)は、画像のピクセル(画素)一つひとつに対して「何が写っているか」の意味ラベル(色)を塗っていくタスクです。
物体検出が物体を「四角い枠(バウンディングボックス)」で大雑把に捉えるのに対し、セグメンテーションは物体の「正確な形・輪郭」を切り出すことができます。
🎨 具体的なイメージ
- Zoomの背景ぼかし:
「人物」の領域だけをピクセル単位で正確に切り抜き、それ以外の「背景」領域にぼかし加工を入れます。 - 自動運転:
カメラ映像を見て、「道路(灰色)」「歩道(赤)」「車(青)」のように視界全体を色分けし、走行可能なエリアを厳密に判定します。
最大の弱点:個体識別はしない
このタスクの重要な特徴は、「同じ種類の物体は、すべて同じ色で塗ってしまう」ことです。
例えば、二人の人が重なっている場合、それらは「1つの大きな人の塊」として認識され、「Aさん」と「Bさん」に区別することはできません。(※個体を区別するのは、次に紹介する「インスタンスセグメンテーション」の役割です)。
代表的なモデル(ここが出ます!)
| モデル名 | 特徴とキーワード |
|---|---|
| FCN (Fully Convolutional Network) |
CNNの最後の「全結合層」を「畳み込み層」に置き換えたモデル。 位置情報を保持したまま出力できるようになった元祖モデル。 |
| U-Net | 医療画像診断(細胞や臓器の抽出)で圧倒的なシェアを誇るモデル。 ネットワークの形がアルファベットの「U」の字に似ているのが名前の由来。 |
| SegNet | エンコーダとデコーダを用いた対称的な構造を持つモデル。道路シーンの解析などで有名。 |
G検定対策
出題ポイント
- 定義:画像の「画素(ピクセル)単位」でクラス分類を行うタスクである。
- U-Net:「医療画像」「少数のデータでも学習可能」「スキップ接続(Skip Connection)」といったキーワードと共に頻出します。
- Up-sampling:畳み込みで小さくなった特徴マップを、元の画像サイズに戻す処理(逆畳み込み / Deconvolution)が必要になる。
ひっかけ対策
- 「個々の物体(インスタンス)を識別できる」→ × 誤り。
「車」というクラス領域は分かりますが、「1台目の車」と「2台目の車」を区別することはできません。それができるのは「インスタンスセグメンテーション」です。 - 「バウンディングボックスを出力する」→ × 誤り。
それは「物体検出」です。セグメンテーションは「マスク画像(塗り分け画像)」を出力します。


📚 より詳細を学びたい方へ

