

オートエンコーダ(自己符号化器)
解説:自分を「要約」して「復元」する
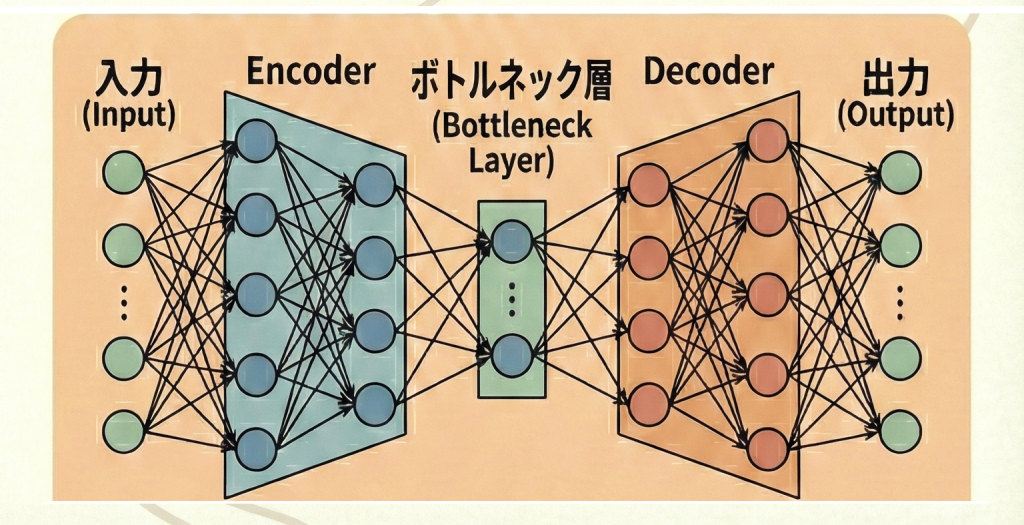
オートエンコーダ(Autoencoder)は、入力されたデータを一度ギュッと圧縮し、そこから再び元のデータを復元するように学習するニューラルネットワークです。
このモデルの目標は「入力と全く同じ出力を出すこと(恒等写像)」です。「コピーするだけなら意味がないのでは?」と思うかもしれませんが、ミソなのは「途中で通り道を狭くしている(ボトルネック)」点です。
⏳ 砂時計のような構造入力層よりも中間層のニューロン数を極端に少なくします。
- エンコーダ(符号化): データを圧縮し、情報の「要約(潜在変数)」を作ります。
- デコーダ(復号): 要約だけを見て、元のデータを必死に再現しようとします。
これにより、ネットワークは「データのノイズや無駄を削ぎ落とし、本質的な特徴だけを記憶する」ことを強制的に学習させられます。
オートエンコーダの3大活用術
ただ圧縮するだけでなく、その性質を利用して様々なタスクに応用されます。
| 用途 | 仕組み |
|---|---|
| 次元削減 | 中間層のデータ(特徴量)を取り出せば、PCAのようにデータをコンパクトに表現できます。 (※活性化関数を使えば非線形な圧縮が可能) |
| 異常検知 | 「正常なデータ」だけで学習させます。 そこに「異常なデータ」を入れると、うまく復元できず「入力と出力の差(再構成誤差)」が大きくなります。これを異常として検知します。 |
| ノイズ除去 (Denoising) |
入力にわざとノイズを乗せ、出力で「きれいな画像」になるよう学習させます。 これにより、不要な汚れを消すフィルタが作れます。 |
G検定対策
出題ポイント
- 学習タイプ:入力データそのものを正解として扱うため、正解ラベル(教師データ)を必要としない「教師なし学習」に分類される。
- 構造:中間層のニューロン数を入力層より少なくすることで、情報を圧縮する。これをボトルネックと呼ぶ。
- 目的:入力と同じ出力を出すこと(恒等写像)を目指すことで、結果的に特徴抽出を行う。
ひっかけ対策
- × 分類問題を解くための教師あり学習である
(解説)「これは犬です」といったラベルは使いません。あくまでデータの特徴を掴むためのモデルです。 - × 中間層を大きくすると性能が上がる
(解説)中間層を入力より大きくすると、単に入力データを丸暗記(コピー)するだけになり、特徴抽出ができません。小さくすることに意味があります。


📚 より詳細を学びたい方へ

