

Self-Attention (自己注意機構)
解説:文脈を「自分の中」で解決する
Self-Attention(自己注意機構)は、「入力された一つの文章(自分自身)」の中で、単語同士が互いにどう関係しているかを計算する仕組みです。現在最強の言語モデルと言われるTransformerやBERTの中核となる技術です。
従来のAttentionは「翻訳元(日本語)」と「翻訳先(英語)」という異なるデータ間での関連を見ていましたが、Self-Attentionは「同じ文の中での単語の関係」を見ます。
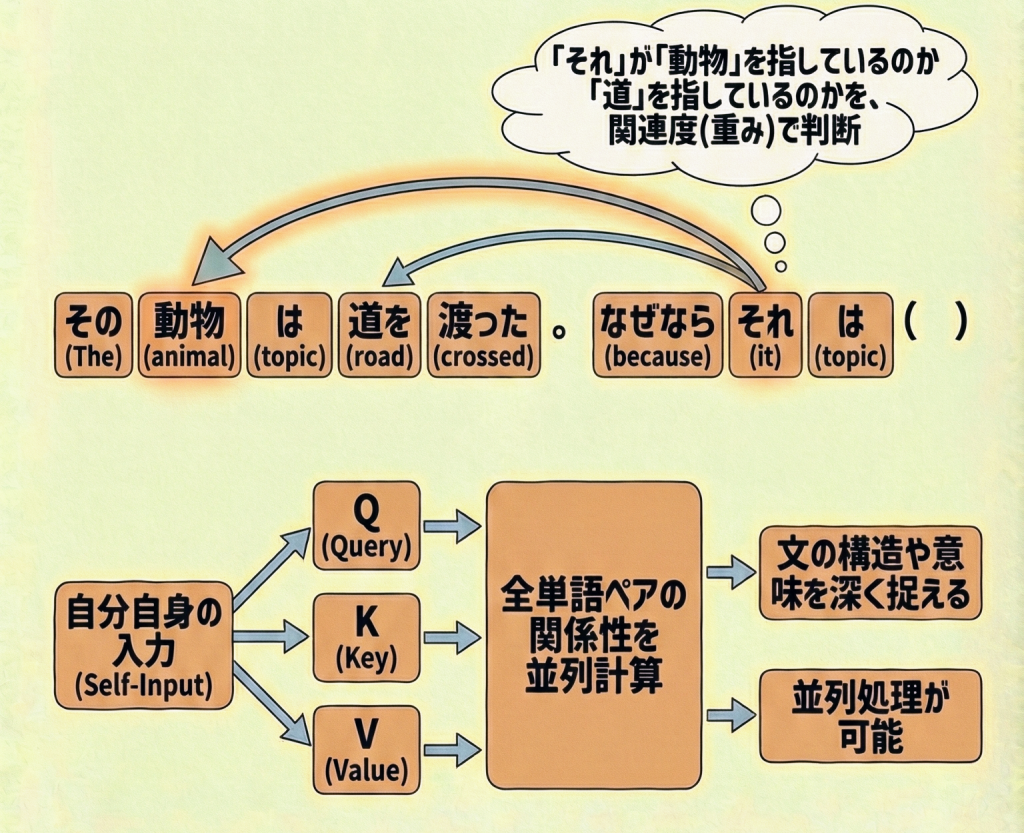
例文:「その動物は道を渡った。なぜなら それ はおなかがすいていたからだ。」この文をAIが読むとき、「それ(it)」が何を指すのかを判断する必要があります。
- Self-Attentionは、「それ」と文中の全単語(動物、道、渡る…)との関連度(内積)を一気に計算します。
- 文脈から「それ」=「動物」であるという強い関連(重み)を発見し、意味を正しく理解します。
なぜRNNより優れているのか?
Self-Attentionの最大の発明は、「距離の壁」と「時間の壁」を壊したことです。
| 比較項目 | RNN (LSTM) | Self-Attention (Transformer) |
|---|---|---|
| 計算の仕方 | 前から順番に計算。 (前の計算が終わるまで次へ行けない) |
並列計算が可能。 (全単語を一斉に計算できるため爆速) |
| 長距離の依存 | 距離が離れると忘れてしまう。 (勾配消失のリスク) |
距離に関係なく直接参照。 (どんなに離れていても1ステップで繋がる) |
G検定対策
出題ポイント
- 定義:Q(クエリ)、K(キー)、V(バリュー)の全てを「同じ入力データ」から生成して計算するAttentionである。
- メリット:文中の離れた位置にある単語同士の関係(長期的な依存関係)を捉えることができる。
- 計算:Softmax関数を使って重みを正規化し、バリュー(V)の加重和として出力を得る。
ひっかけ対策
- × 異なる言語間(英語と日本語など)の関係を計算する
(解説)それは通常のAttention(またはSource-Target Attention / Cross Attention)の説明です。Self-Attentionはあくまで「同一言語(同一データ)内」での計算です。 - × 単語の語順(位置情報)を自動的に認識できる
(解説)Self-Attention自体には順序を認識する能力がありません(「私は猫」と「猫は私」が同じ計算結果になってしまう)。そのため、必ず「Position Encoding(位置エンコーディング)」とセットで使われます。


📚 より詳細を学びたい方へ

