

方策(Policy)
解説
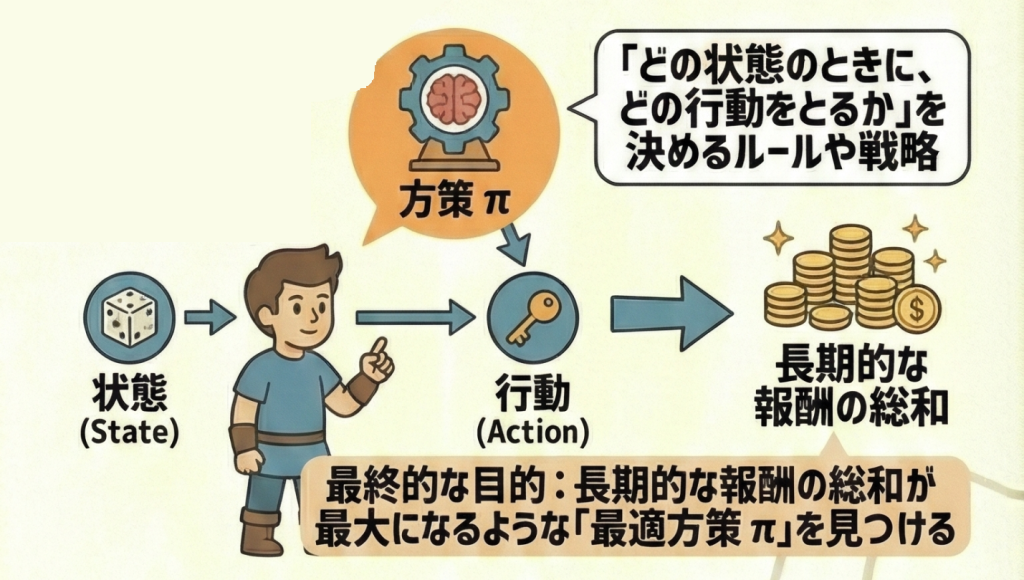
方策(Policy)とは、強化学習のエージェントが「ある状態において、どのような行動をとるか」を決めるための「戦略」や「ルールブック」のことです。通常、ギリシャ文字のπ(パイ) で表されます。
エージェントは、この方策 π に従って行動を選択します。強化学習の最終的な目的は、将来もらえる報酬の合計(割引現在価値)が最大になるような「最強のルールブック(最適方策)」を見つけ出すことです。
方策の2つのタイプ
方策には大きく分けて2種類あります。G検定ではこの違いを理解しているかが問われます。
| 種類 | 特徴 | 具体例 |
|---|---|---|
| 決定論的方策 (Deterministic Policy) |
「この状態なら、必ずこの行動をする」と一意に決まっている。 | 「右へ進め」 (迷うことなく右を選ぶ) |
| 確率的方策 (Stochastic Policy) |
「80%で右、20%で左」のように確率で行動を決める。 | 「たぶん右がいいけど、たまには左も探索してみよう」 |
価値関数との関係
「方策」と「価値関数」は切っても切れない関係にあります。
- 方策(Policy):どう動くかを決める(行動主体)。
- 価値関数(Value Function):その方策がどれくらい良いかを評価する(評価者)。
強化学習では、「今の方策を価値関数で評価する」→「より良い方策に修正する」→「また評価する」……というサイクル(方策反復法など)を繰り返して、最適方策を目指します。
G検定対策
出題ポイント
- 定義:方策は「状態から 行動への写像(マッピング)」である。
- 最適方策(Optimal Policy):期待収益(割引現在価値の総和)を最大化するような方策のこと。
- 探索(Exploration):学習初期などでは、あえて「確率的方策」を使っていろいろな行動を試すこと(探索)が重要になる。
ひっかけ対策・注意点
- × 価値関数と同じである
(解説)価値関数は「その状態の良さ(数値)」を表すもの、方策は「どう動くか(ルール)」を表すものです。別物です。 - × 最適方策は常に1つだけである
(解説)報酬が最大になるルートが複数ある場合(例:右から行っても左から行っても同じ距離でゴールできる)、最適方策も複数存在する可能性があります。


📚 より詳細を学びたい方へ

