

クラスタリング(Clustering)
1. 解説
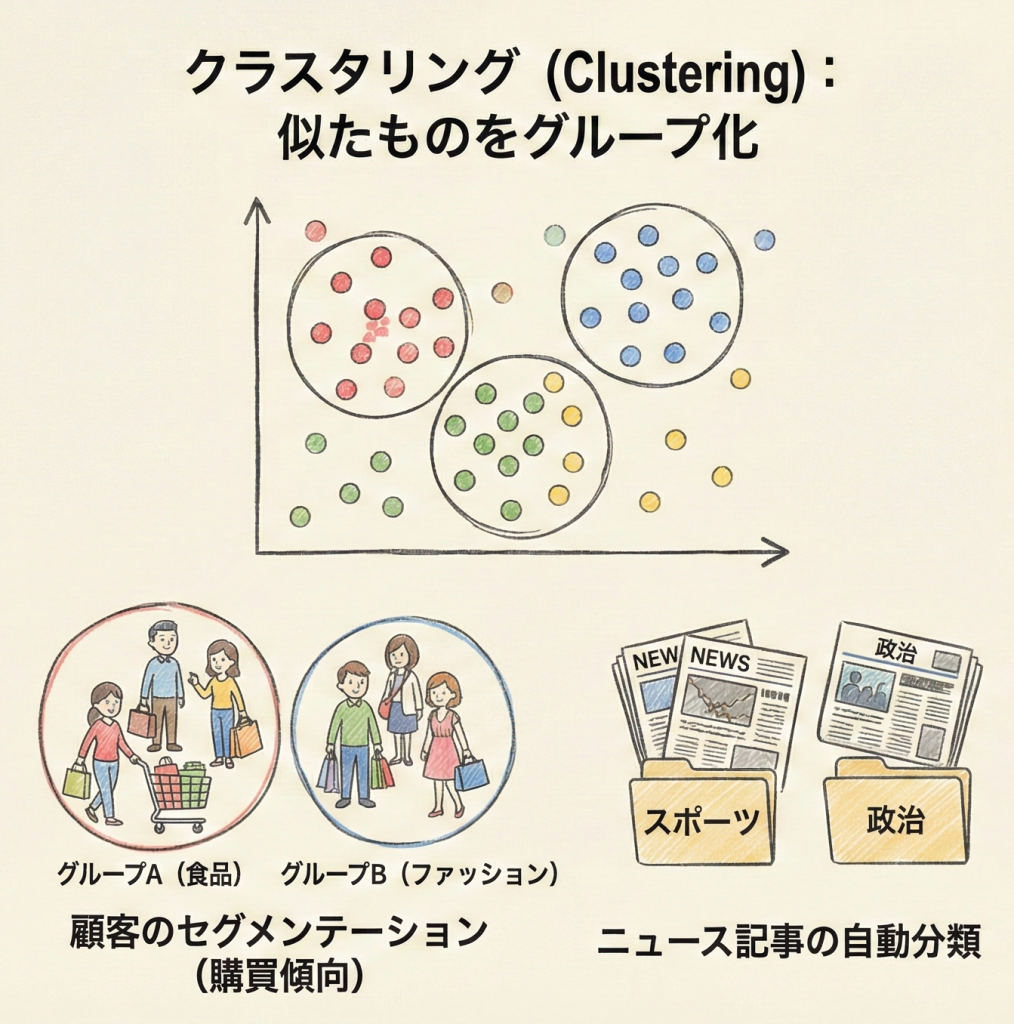
クラスタリング(クラスター分析)とは、データの中から「似ているもの同士」を自動的に集めてグループ分け(クラスター化)する手法です。
最大の特徴は、正解データ(「これはAです」というラベル)を与えない「教師なし学習」である点です。AIは「何が正解か」を知らされないまま、データの形状や距離だけを見て「このデータとこのデータは近いから同じ仲間だろう」と判断します。
「分類」と「クラスタリング」の違い
「分ける」という点は同じですが、アプローチが正反対です。
| 項目 | 分類(Classification) | クラスタリング(Clustering) |
|---|---|---|
| 学習タイプ | 教師あり学習 | 教師なし学習 |
| 正解ラベル | あり(例:犬、猫) | なし(データの中身のみ) |
| 目的 | 新しいデータがどのカテゴリかを予測する | データ全体の構造や類似性を発見する |
| 具体例 | 迷惑メールフィルタ | 顧客のセグメンテーション(優良顧客・離脱層などの発見) |
クラスタリングの2大手法
G検定では、以下の2つの手法の違いがよく問われます。
| 種類 | 代表的なアルゴリズム | 特徴・キーワード |
|---|---|---|
| 非階層的手法 | k-means法 (k平均法) |
・あらかじめクラスター数(k)を決める必要がある。 ・ビッグデータでも計算が速い。 ・エルボー法で最適なkを探す。 |
| 階層的手法 | ウォード法 (Ward法) |
・似ているものから順にくっつけていく。 ・デンドログラム(樹形図)が作れる。 ・計算量が重く、ビッグデータには不向き。 |
2. G検定対策
出題ポイント
- k-means法の仕組み:
データをランダムにk個のグループに分け、「重心(中心)」を更新しながらグループを修正していく反復アルゴリズムです。初期値に結果が左右されやすい欠点があります(対策:k-means++)。 - 距離の定義:
「似ている」と判断するために、通常はユークリッド距離(直線距離)などが使われます。 - エルボー法:
k-meansで「いくつのグループに分けるのがベストか(kの数)」を決める際に、グラフの折れ曲がり具合を見て判断する手法。
ひっかけ対策・注意点
- × クラスタリングが「このグループは富裕層だ」と教えてくれる
(解説)クラスタリングは「グループ分け」をしてくれるだけです。そのグループが「何を意味するのか(富裕層なのか、若者層なのか)」の意味づけ(解釈)は人間が行う必要があります。 - × 分類問題との混同
問題文に「正解ラベルを用いて〜」とあったら分類(教師あり)、「データの類似度に基づいて〜」とあったらクラスタリング(教師なし)です。


📚 より詳細を学びたい方へ

