

AlphaGo(アルファ碁)
解説
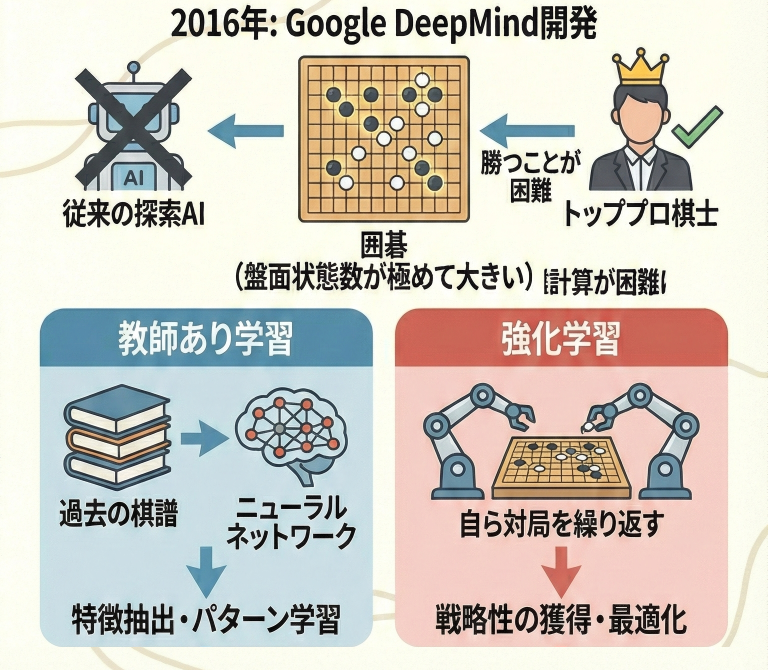
AlphaGo(アルファ碁)とは、Google DeepMind社によって開発された囲碁AIプログラムです。2016年、世界トップ棋士であるイ・セドル(Lee Sedol)九段に4勝1敗で勝利したことで、第3次AIブームを象徴する存在となりました。
最強の仕組み:DL × 強化学習 × 探索
囲碁は盤面が広すぎて(19×19)、従来の探索手法では人間には勝てないとされていました。AlphaGoは、以下の技術を組み合わせることでその壁を突破しました。
- モンテカルロ木探索(MCTS):ランダムなシミュレーションで有利な手を探索するベース技術。
- Policy Network(方策ネットワーク):「次はどこに打つべきか」という候補手を絞り込む(探索の幅を狭める)。
- Value Network(価値ネットワーク):「現在の盤面はどちらが有利か」という勝率を評価する(探索の深さを浅くする)。
学習のプロセス
AlphaGoは、まず人間のプロ棋士の棋譜を真似る「教師あり学習」を行い、その後、自分自身と対局を繰り返す「強化学習」によって強さを磨き上げました。
G検定対策
出題ポイント
- 構成要素:「Policy Network(方策)」と「Value Network(価値)」の2つのCNNを使用。
- 学習手法:人間の棋譜による「教師あり学習」+自己対局による「強化学習」。
- 後継機(AlphaGo Zero):人間の棋譜(教師データ)を一切使わず、ルールのみを教えて自己対局だけで最強になったモデル。ここが試験でよく問われる違いです。
よくあるひっかけ問題
- × AlphaGoは、人間の棋譜を使わずにゼロから学習した
(解説)それは後継機の「AlphaGo Zero」の説明です。無印のAlphaGoは人間の棋譜を使っています。 - × AlphaGoは、チェスの世界チャンピオンに勝利した
(解説)チェスはIBMの「Deep Blue」です。AlphaGoは囲碁です。


📚 より詳細を学びたい方へ

