

Attention(注意機構)
解説:AIに「メリハリ」を与える技術
Attention(アテンション)は、入力データの中で「今、どこに注目すべきか」をAI自身に判断させる仕組みです。
人間が翻訳をする時、文章を頭からお尻まで丸暗記してから翻訳するわけではありません。「私は猫です」を「I am a cat」に訳す時、「cat」と書く瞬間は、元の文の「猫」という単語をチラッと見返しているはずです。
Attentionは、まさにこの「必要な時に、必要な場所をチラ見する(注目する)」動作を数式で再現したものです。
解決した「固定長の壁」問題
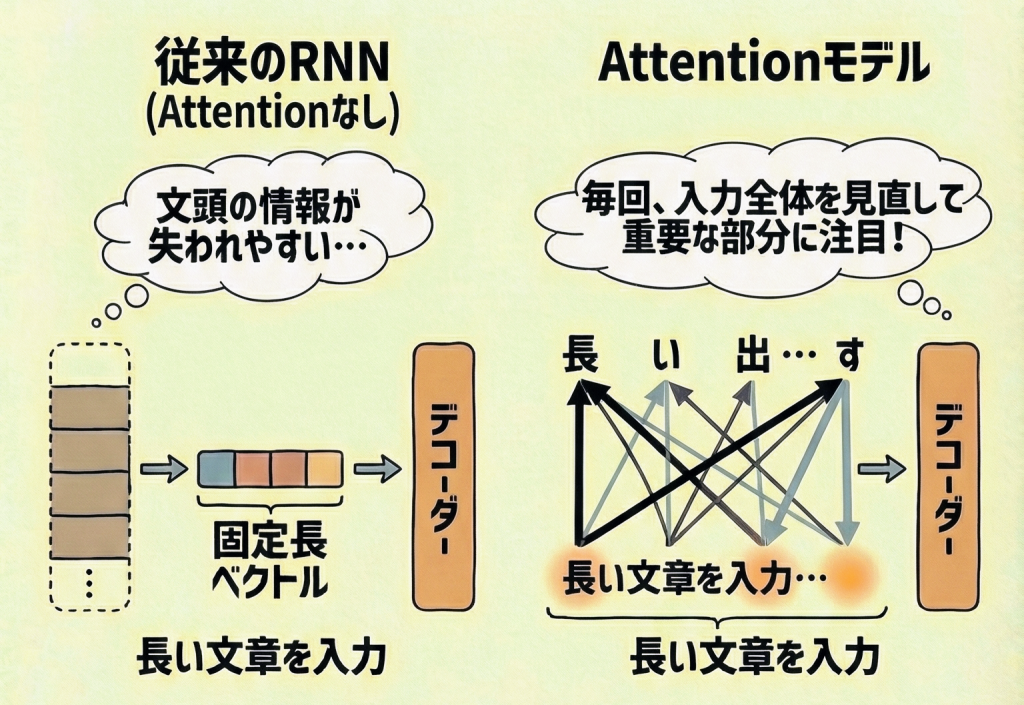
Attentionが登場する前(2014年以前)の翻訳AI(Seq2Seqモデル)には、ある致命的な欠点がありました。
🚫 従来の課題(ボトルネック)
どんなに長い小説でも、無理やり「固定長のベクトル(一つの数値の塊)」に圧縮しなければなりませんでした。
その結果、長い文章だと最初のほうの内容が押しつぶされて消えてしまい、翻訳精度がガタ落ちしていました。
どんなに長い小説でも、無理やり「固定長のベクトル(一つの数値の塊)」に圧縮しなければなりませんでした。
その結果、長い文章だと最初のほうの内容が押しつぶされて消えてしまい、翻訳精度がガタ落ちしていました。
✅ Attentionによる解決
無理に一つに圧縮するのをやめました。
代わりに、単語ごとの情報をすべて残しておき、「出力するたびに、入力文全体を検索(スキャン)して、関連度の高い単語の情報を引っ張ってくる」ようにしました。
これにより、どれだけ長い文章でも、文脈を正確に捉えられるようになりました。
無理に一つに圧縮するのをやめました。
代わりに、単語ごとの情報をすべて残しておき、「出力するたびに、入力文全体を検索(スキャン)して、関連度の高い単語の情報を引っ張ってくる」ようにしました。
これにより、どれだけ長い文章でも、文脈を正確に捉えられるようになりました。
RNN vs Attention のイメージ比較
| 比較項目 | 従来のRNN (Seq2Seq) | Attention |
|---|---|---|
| 情報の持ち方 | 全てを1つのベクトルに詰め込む。 (バケツリレーで最後の人だけが全情報を持つ) |
個々の単語情報を全て保持する。 (全員の顔を見渡せる状態) |
| 処理の仕方 | 最後の情報だけを頼りにする。 | 関連度(重み)を計算し、重要な部分だけを強く参照する。 |
| 長文対応 | 苦手(情報が消える)。 | 得意(どこでも参照できる)。 |
G検定対策
出題ポイント
- 定義:入力データの中で、予測に貢献する重要な部分を動的に特定し、「重み(Attention Weight)」をつけて利用する仕組み。
- 歴史的意義:Encoder-Decoderモデル(Seq2Seq)の抱えていた「固定長ベクトルのボトルネック」を解消した。
- 発展:後にRNNを完全に排除した「Transformer」(BERTやGPTの基礎)へと進化した。
ひっかけ対策
- × Attentionは入力を前から順番に処理しなければならない
(解説)Attention自体は、入力全体を一度に見渡して計算できるため、並列処理との相性が抜群です。(これがTransformerでの高速化に繋がります)。 - × RNNと一緒には使えない
(解説)元々は「RNNベースのSeq2Seq」の性能を上げるための追加パーツとして提案されました。現在はAttention単独(Self-Attention)で使うのが主流ですが、RNNと組み合わせることも可能です。
