マルコフ決定過程(MDP:Markov Decision Process)
解説
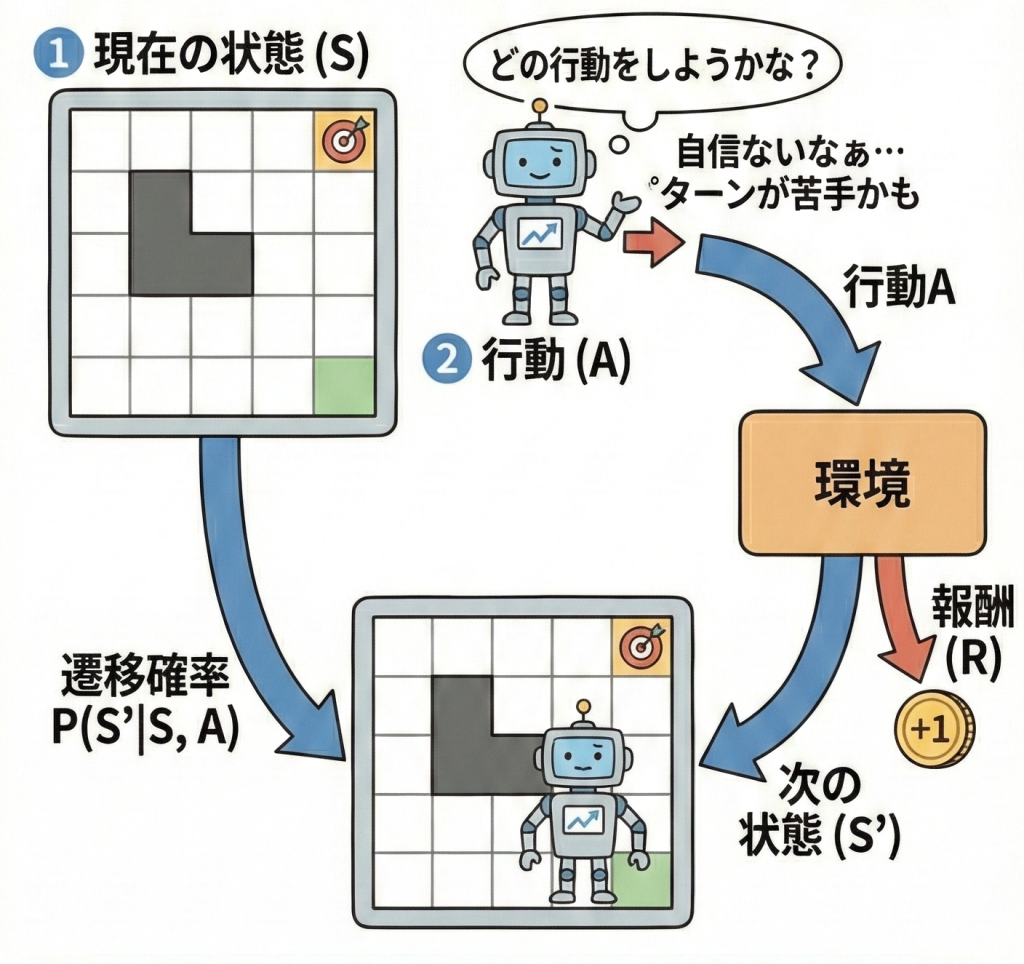
マルコフ決定過程(MDP)とは、強化学習の問題を数学的に表現するための「舞台設定」や「ルールブック」のようなものです。
「マルコフ性(未来は現在のみに依存する)」を満たす環境の中で、エージェント(AI)がどのような行動をとれば報酬を最大化できるかを考えるための枠組みです。
MDPを構成する4つの要素
MDPは、主に以下の4つの要素で定義されます。G検定ではこの組み合わせが頻出です。
| 要素 | 記号 | 意味・具体例 |
|---|---|---|
| 状態 (State) |
S | 今どうなっているか。 (例:将棋の盤面、ロボットの位置) |
| 行動 (Action) |
A | エージェントができること。 (例:駒を動かす、右に進む) |
| 遷移確率 (Transition) |
T | 行動した結果、次の状態へ移る確率。 (例:80%の確率で前に進み、20%で滑る) |
| 報酬 (Reward) |
R | その行動が良かったのか悪かったのかの評価値。 (例:ゴールしたら+100、壁にぶつかったら-10) |
G検定対策
出題ポイント
- 定義:MDPは「状態・行動・遷移確率・報酬」の4つ(場合によっては割引率を含めて5つ)で構成される。
- 目的:エージェントは、MDPの環境下で、将来もらえる報酬の総和(割引現在価値)が最大になるような「方策(どう行動するか)」を学習することを目指す。
ひっかけ対策・注意点
- 過去の履歴:
「過去の履歴を使わない」というのは「過去のデータは不要」という意味ではなく、「現在の状態の中に、過去の経緯も含めた必要な情報が全て集約されている(マルコフ性)」という前提条件を指します。