

強化学習 (Reinforcement Learning)
解説
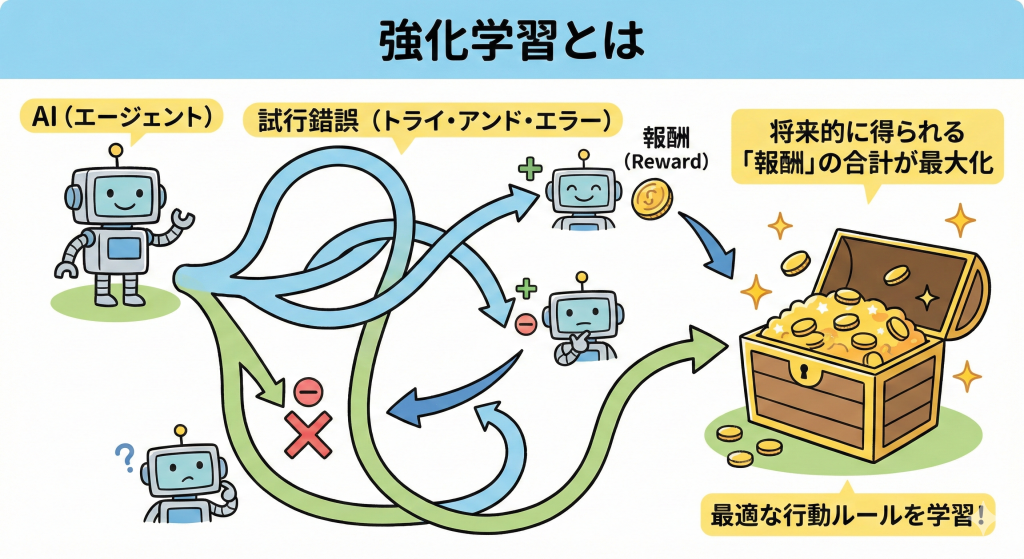
強化学習とは、AI(エージェント)が試行錯誤(トライ・アンド・エラー)を繰り返しながら、将来的に得られる「報酬(Reward)」の合計が最大になるような行動ルールを学習する手法です。
「アメとムチ」で学ぶ
犬のしつけに例えられます。「お手」と言われて正しく手を出せば「おやつ(報酬)」がもらえ、間違った行動をすれば何ももらえません。
エージェントは環境の状態(State)を見て行動(Action)を選択し、その結果として報酬が得られるか、あるいは罰せられるかによって、徐々に「どの状況でどう動けば最も得をするか」を学習していきます。
探索と利用のトレードオフ
強化学習の最大の課題は、「探索(Exploration)」と「利用(Exploitation)」のバランスです。
- 利用:過去の経験から「一番良い」と分かっている行動だけを選び続けること(確実だが、成長がない)。
- 探索:あえて失敗するかもしれない未知の行動を試すこと(リスクはあるが、より大きな報酬が見つかる可能性がある)。
この2つのバランスをどう取るかが、賢いAIを作る鍵となります。
G検定対策
出題ポイント
- 基本サイクル:「エージェント(AI)」が「環境」に行動を起こし、「報酬」と「次の状態」を受け取るループ。
- 目的:即時の報酬ではなく、「将来にわたって得られる報酬の総和(割引現在価値)」を最大化すること。
- キーワード:
- Q学習(Q-Learning):行動の価値(Q値)をテーブルで管理する代表的な手法。
- バンディット問題:「探索と利用のトレードオフ」を考える古典的な例題(複数のスロットマシンからどれを選ぶか)。
よくあるひっかけ問題
- × 強化学習は、正解データ(教師データ)を与えて学習させる手法である
(解説)それは「教師あり学習」です。強化学習には「正解」はなく、「報酬(点数)」があるだけです。「どうすれば正解か」は自分で探さなければなりません。 - × 常に過去の経験に基づいた最善の行動だけを取り続けるのが最適である
(解説)それだけでは「利用(Exploitation)」に偏ってしまい、局所的な最適解に陥ります。未知の可能性を探る「探索(Exploration)」も必要です。


📚 より詳細を学びたい方へ

