

ファインチューニング (Fine-tuning)
解説:「プロ」を再教育して「専門家」にする
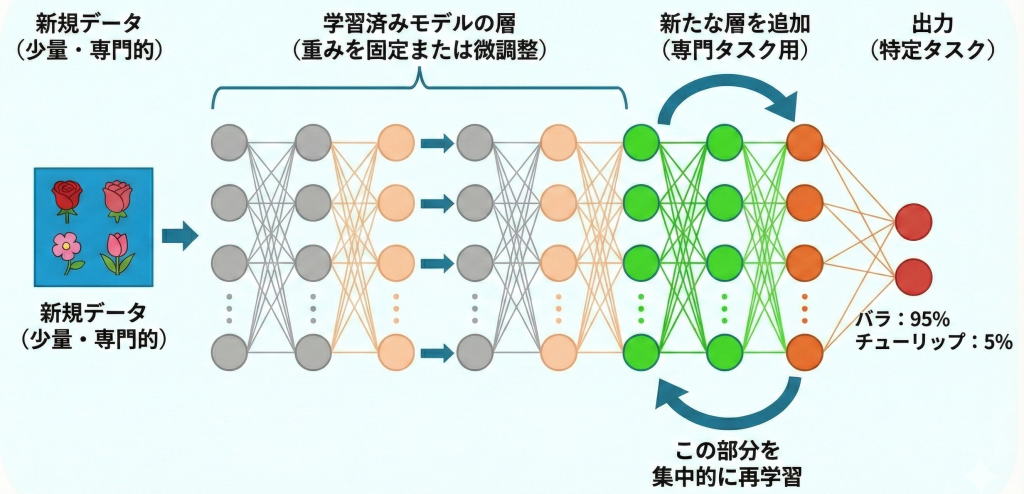
ファインチューニング(微調整)は、学習済みのモデル(事前学習モデル)の重みデータを「初期値」として使い、新しいタスクに合わせて再学習(パラメータの更新)を行う手法です。
転移学習の一種ですが、単にモデルを「知識の引き出し(特徴抽出器)」として使うだけでなく、モデルの中身自体を少し書き換えて(微調整して)、新しいタスクに特化させる点に特徴があります。
👨🍳 シェフの例え
- ゼロから学習: 包丁の持ち方から教える(時間がかかる)。
- ファインチューニング: すでに「フレンチの達人(学習済みモデル)」であるシェフに、「イタリアン」を教える。
彼は「食材の切り方」や「火の通し方」といった基礎能力(下位層)は既に完璧なので、教える必要はありません(重みを固定)。
「イタリアンの味付け」という仕上げの部分(上位層)だけを特訓すれば、短期間でイタリアンの達人になれます。
どの層を再学習させるか?
ディープラーニングの層には役割の違いがあります。これを理解するのが合格の鍵です。
- 入力に近い層(下位層):「線」「色」「模様」などの汎用的な特徴を見る。
→ どんな画像でも共通して使えるので、重みを固定(Freeze)することが多い。 - 出力に近い層(上位層):「目」「タイヤ」などの具体的な物体のパーツを見る。
→ タスクによって見るべきものが違うので、再学習(Unfreeze)させる。
| 手法 | 学習コスト | 精度 |
|---|---|---|
| ゼロから学習 (Scratch) |
高い (大量のデータと時間が必要) |
データが十分なら高いが、少ないと低い。 |
| ファインチューニング | 低い (少データ・短時間で済む) |
少データでも非常に高い精度が出やすい。 |
G検定対策
出題ポイント
- 初期値:ランダムな値から始めるのではなく、「学習済みモデルの重みパラメータ」を初期値として利用する。
- 学習率:すでに賢い状態からスタートするため、学習率(Learning Rate)はゼロから学習する時よりも「小さく」設定するのが一般的。大きくしすぎると、せっかくの事前の知識が壊れてしまう(破滅的忘却)。
- 層の固定:データ量が少ない場合は、多くの層を固定し、出力層付近のみを学習させる。データ量が十分ある場合は、全層を微調整することもある。
ひっかけ対策
- × すべての層を必ず再学習させる必要がある
(解説)計算コスト削減や過学習防止のため、下位層を固定(フリーズ)するのが一般的です。 - × 転移学習とは無関係である
(解説)ファインチューニングは、転移学習を実現するための「具体的な手段の一つ」です。


📚 より詳細を学びたい方へ

