

物体検出 (Object Detection)
解説:「何が」「どこに」あるかを瞬時に見抜く
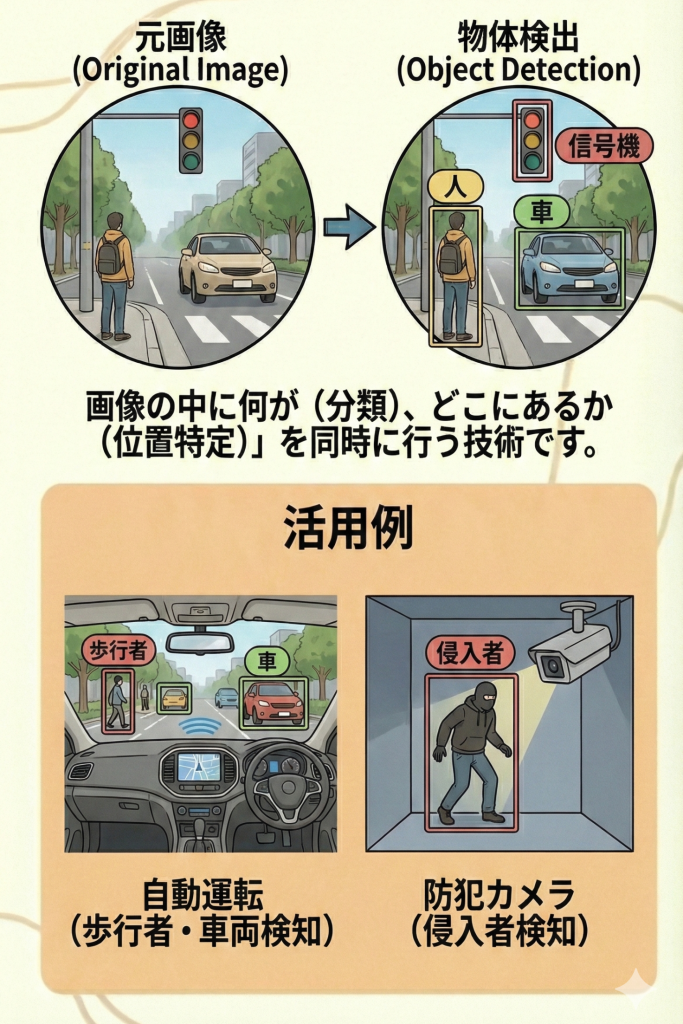
物体検出は、画像の中に写っている物体の「種類(クラス分類)」と「位置(位置特定)」を同時に特定するタスクです。
画像分類が「この画像は犬です」と画像全体に対して答えるのに対し、物体検出は「ここに犬がいて、あそこに車がある」といった具合に、複数の物体をそれぞれの場所とともに検出します。
📦 キーワード:バウンディングボックス (Bounding Box)
検出した物体を囲む「長方形の枠」のことです。
AIは、この枠の「座標(X, Y)」と「大きさ(幅, 高さ)」、そして「中身が何か(クラス)」を出力します。
検出した物体を囲む「長方形の枠」のことです。
AIは、この枠の「座標(X, Y)」と「大きさ(幅, 高さ)」、そして「中身が何か(クラス)」を出力します。
2つの主要なアルゴリズム系統
物体検出のモデルは、処理のプロセスによって大きく2つに分類されます。ここが試験の頻出ポイントです。
| タイプ | 代表モデル | 特徴 |
|---|---|---|
| 2段階検出 (Two-stage) |
R-CNNシリーズ (R-CNN, Fast R-CNN, Faster R-CNN) |
「候補領域の提案」→「分類」の2ステップで行う。 精度は高いが、速度は遅め。 |
| 1段階検出 (One-stage) |
YOLOシリーズ SSD (Single Shot MultiBox Detector) |
領域提案と分類を同時に行う。 精度はそこそこだが、速度が非常に速い。 (リアルタイム処理向け) |
G検定対策
出題ポイント
- タスク定義:「Classification(分類)」+「Localization(位置特定)」を同時に行う。
- 評価指標:
- IoU (Intersection over Union):「正解の枠」と「予測した枠」がどれくらい重なっているかを示す指標(重なり具合)。
- mAP (mean Average Precision):物体検出モデルの総合的な性能評価に使われる指標。
- モデルの違い:「YOLOやSSDは高速(1段階)」、「R-CNN系は高精度(2段階)」という対比を覚える。
ひっかけ対策
- 「物体検出はピクセル単位で物体の形を切り抜く」→ × 誤り。
それは「セマンティック・セグメンテーション」などの説明です。物体検出はあくまで「四角い枠(矩形)」で大まかな位置を示します。 - 「YOLOは精度重視で処理が重い」→ × 誤り。
YOLO (You Only Look Once) は「一度見るだけ」という名前の通り、速度重視のモデルです。


📚 より詳細を学びたい方へ

