

Seq2Seq(Sequence-to-Sequence)
解説:2人でバケツリレーする翻訳家
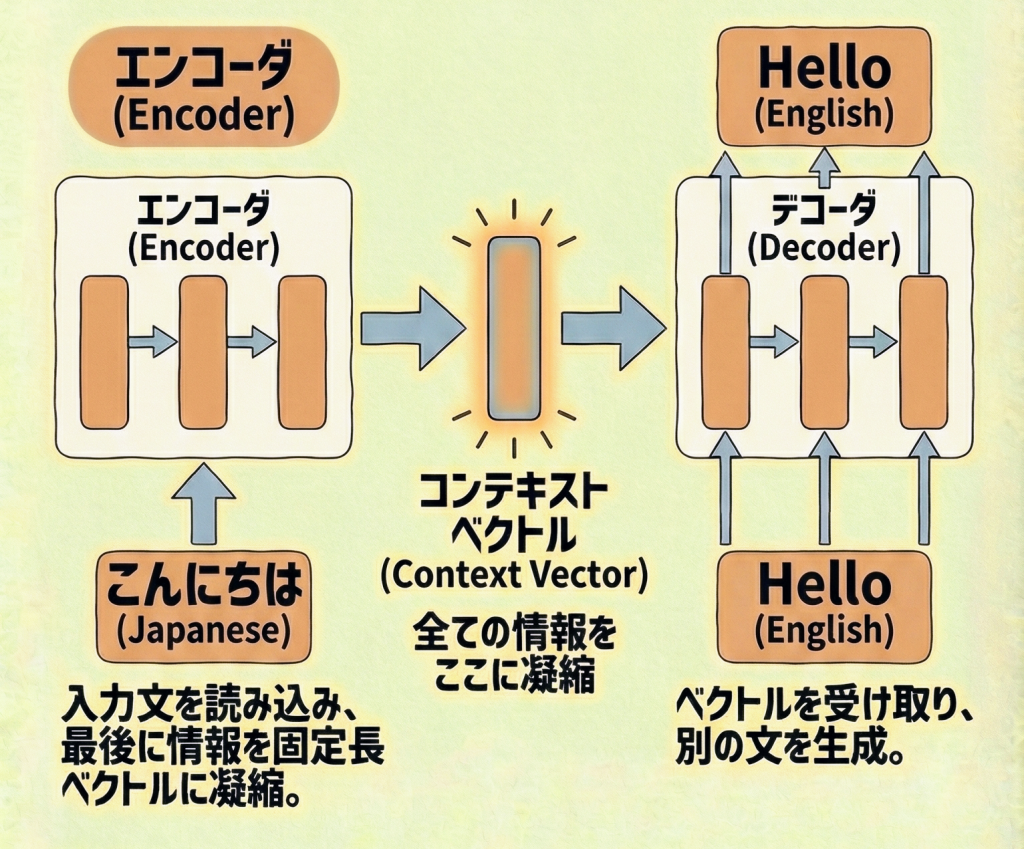
Seq2Seq(シーク・ツー・シーク)は、ある時系列データを、別の時系列データに変換するモデルです。主に「エンコーダ(Encoder)」と「デコーダ(Decoder)」という2つのネットワークをつなげた構造をしています。
これを「日本語を英語に翻訳する作業」に例えてみましょう。
🗣️ 翻訳の流れ(エンコーダ・デコーダモデル)
- エンコーダ(読み手):
日本語の文章を最後まで読み込み、その意味を「たった一つの数値の塊(コンテキストベクトル)」に圧縮して記憶します。
(「ふむふむ、要するにこういう意味だな」と頭に入れる) - デコーダ(書き手):
渡された「数値の塊」だけを頼りに、英語の文章を一から生成します。
(記憶した意味をもとに、英語として喋りだす)
最大の弱点:「詰め込みすぎ」問題
初期のSeq2Seq(RNNベース)には、大きな欠点がありました。
エンコーダは、どんなに長い小説でも、固定された長さのベクトル(例えば1024個の数字)に無理やり圧縮しなければなりません。これでは、「長い文章だと、最初の方の内容が入りきらずに消えてしまう」という情報のボトルネックが発生します。
※この限界を突破するために、「Attention(注意機構)」が開発されました。
| 構成要素 | 役割 |
|---|---|
| エンコーダ (Encoder) |
入力を「符号化(Encode)」する。 時系列データを、固定長の内部状態(ベクトル)に変換する役割。 |
| デコーダ (Decoder) |
出力を「復号(Decode)」する。 受け取ったベクトルから、別の時系列データを生成する役割。 |
G検定対策
出題ポイント
- 構造:「エンコーダ(入力処理)」と「デコーダ(出力生成)」の2つで構成される。
- 用途:翻訳(英→日)、対話(質問→回答)、要約(長文→短文)など、「入力も出力も時系列データ」であるタスクに使われる。
- 進化:初期はRNN(LSTM)を使っていたが、後にAttentionが追加され、現在はTransformerへと進化している。
ひっかけ対策
- × 入力と出力の長さは同じでなければならない
(解説)「Sequence-to-Sequence」の名前の通り、長さが違う系列同士(例:長い日本語を短い英語にする)の変換が可能です。 - × 必ずCNNを使用する
(解説)伝統的にはRNNが使われてきました(CNNを使うモデルもありますが必須ではありません)。


📚 より詳細を学びたい方へ

