

Transformer
解説:AIの歴史を変えた「常識破り」のモデル
Transformerは、2017年にGoogleの研究チームが発表した論文『Attention Is All You Need(必要なのはAttentionだけ)』で提案されたモデルです。
それまでの自然言語処理は「RNN(リカレントニューラルネットワーク)」を使うのが常識でしたが、Transformerはこの常識を覆し、「RNNを一切使わず、Attentionだけで構成する」という大胆な手法をとりました。これにより、AIの性能と学習速度が劇的に向上しました。
🚀 RNNとの最大の違い:並列処理
- RNN(旧来):「リレー方式」。前の単語の計算が終わらないと、次の単語に進めない。
→ 計算が遅く、GPUの性能を活かしきれない。 - Transformer(革新):「合唱方式」。文章全体の全単語を「せーの」で一気に(並列に)計算する。
→ GPUで超高速に学習でき、膨大なデータセット(Web全体など)を学習可能にした。
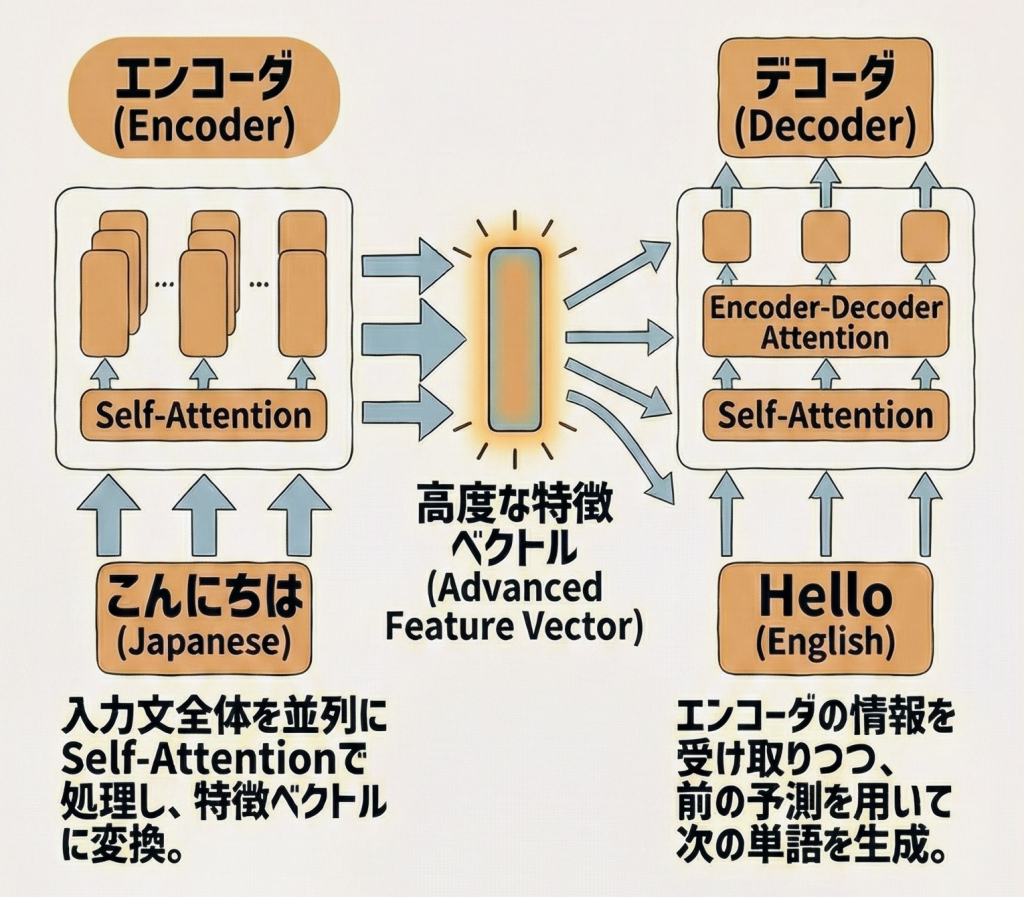
エンコーダとデコーダの役割
Transformerは大きく2つのパーツで構成されており、それぞれが後の有名モデルの基礎となりました。
| パーツ | 役割と仕組み | 派生モデル |
|---|---|---|
| エンコーダ (Encoder) |
「理解担当」 入力文章を一気に読み込み、文脈や意味を理解して特徴ベクトルに変換します。Self-Attentionをフル活用します。 |
BERT (文章理解、分類など) |
| デコーダ (Decoder) |
「生成担当」 エンコーダの理解結果を受け取り、単語を1つずつ順番に予測して文章を作ります。 |
GPTシリーズ (文章生成、チャット) |
G検定対策
出題ポイント
- 論文名:『Attention Is All You Need』(2017年)が頻出です。
- 構造:RNNやCNNを使わず、「Self-Attention」と「Position-wise Feed-Forward Networks」が中心。
- Masked Self-Attention:デコーダ側で使われる特殊なAttention。「学習中に、まだ生成していない未来の単語をカンニングしないように、マスク(目隠し)をする」機能のこと。
- Positional Encoding:並列処理で失われる語順情報を補うために追加される。
ひっかけ対策
- × RNNの性能を改善したモデルである
(解説)RNNを「捨てた」モデルです。ここが最大のポイントです。 - × エンコーダのみで構成されている
(解説)オリジナルのTransformerは「エンコーダ+デコーダ」です。(※BERTはエンコーダのみ、GPTはデコーダのみを使った派生モデルです)。


📚 より詳細を学びたい方へ

