

正則化
解説
過学習を防ぐ「正則化(正規化)」とは?
機械学習のモデルが、訓練データを一生懸命覚えようとするあまり、データに含まれるノイズ(偶然の誤差)まで丸暗記してしまうことがあります。これを過学習(オーバーフィッティング)と呼びます。
過学習を防ぐために、「パラメーター(重み)」の値が大きくなりすぎないように「ペナルティ(罰則)」を与える手法を正則化と呼びます。
主にL1正則化とL2正則化の2種類があります。
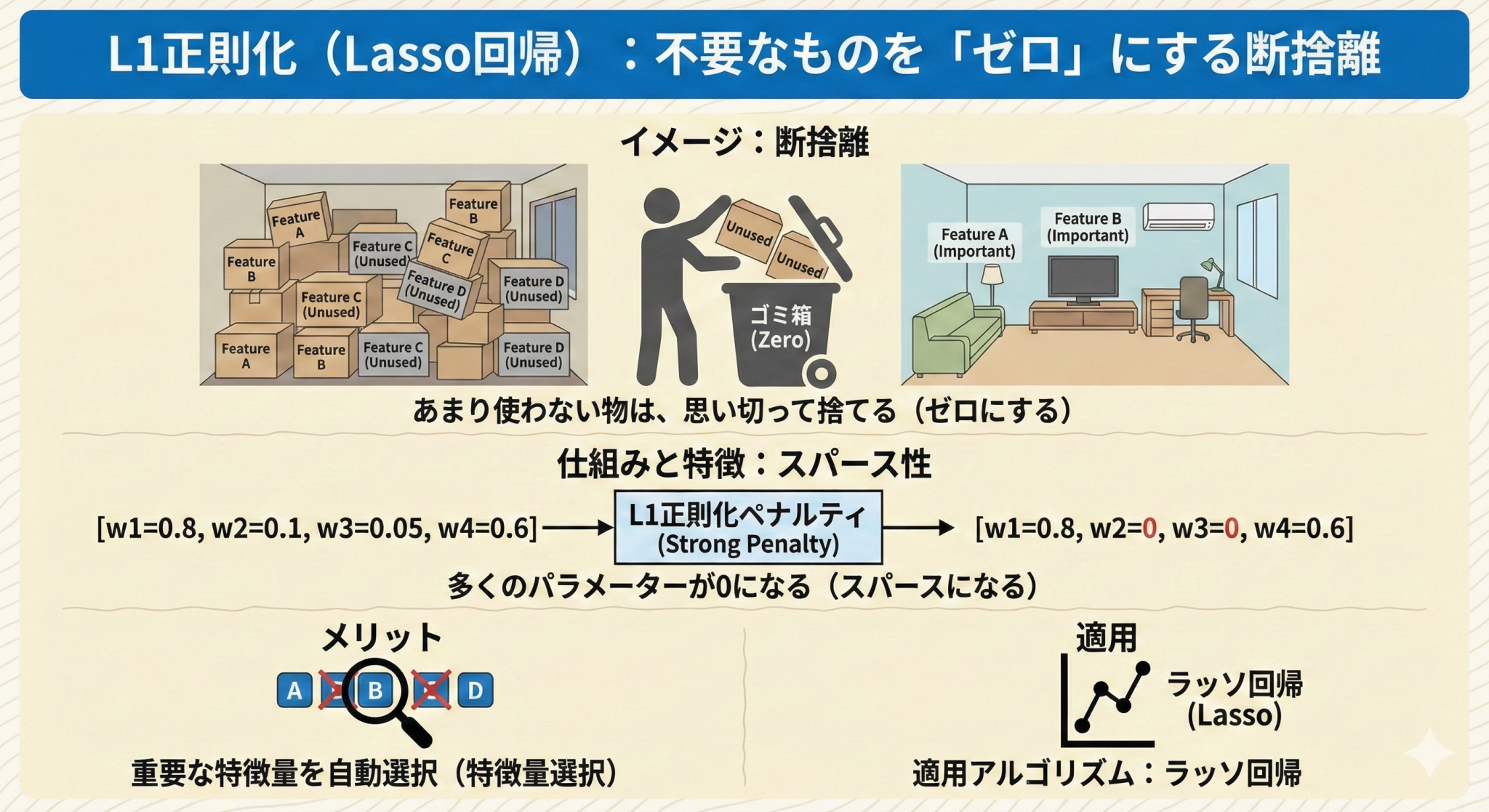
L1正則化(Lasso回帰):不要なものを「ゼロ」にする断捨離
L1正則化は、「一部の重みを完全に0にする」という強力な効果を持っています。
- イメージ:不要な荷物を完全に捨てて、身軽にする「断捨離」。
- 特徴:予測にあまり関係ない変数の重みが「0」になります。つまり、変数の数が減り(スパース化)、モデルがシンプルになります。
- メリット:「どの変数が重要か」が分かりやすくなる(特徴量選択ができる)。
- 適用されるアルゴリズム:ラッソ回帰 (Lasso)
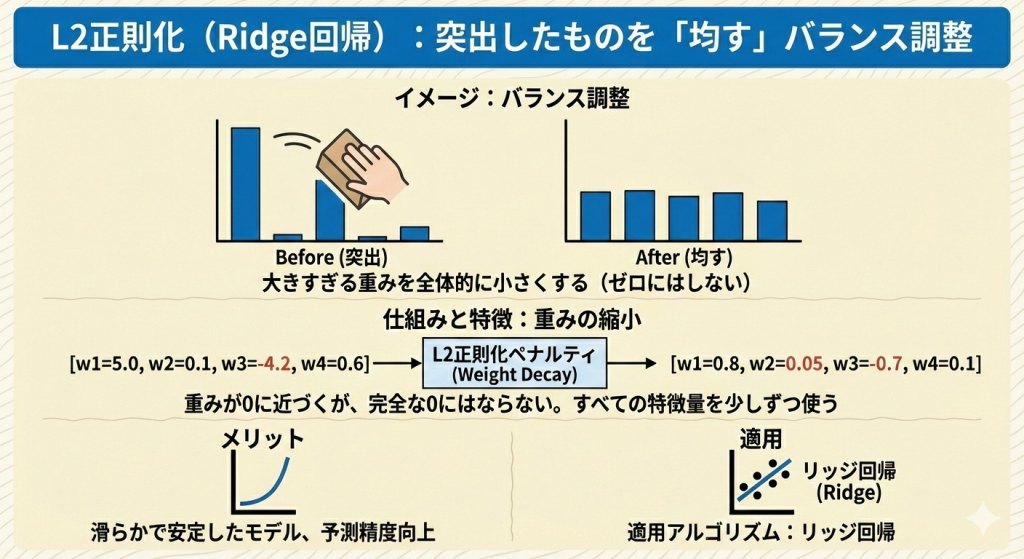
L2正則化(Ridge回帰):突出したものを「均す」バランス調整
L2正則化は、「大きすぎる重みを全体的に小さくする(ゼロにはしない)」というペナルティを与えます。
- イメージ:一部の能力だけが突出しないように、全体を「平均的にバランスよく育てる」。
- 特徴:重みが0に近づきますが、完全な0にはなりません。すべての特徴量を少しずつ使いながら、極端な予測をするのを防ぎます。
- メリット:滑らかで安定したモデルになり、予測精度が高くなりやすいです。
- 適用されるアルゴリズム:リッジ回帰 (Ridge)
まとめ
L1正則化とL2正則化は、どちらも過学習を防ぐための手法ですが、アプローチが異なります。
変数を減らしてモデルをシンプルにしたい場合はL1正則化(ラッソ回帰)、すべての変数を活かしつつ精度を高めたい場合はL2正則化(リッジ回帰)を使うと覚えておきましょう。
G検定対策
出題ポイント
- L1正規化、L2正規化の違いをしっかり覚えておきましょう。
項目 L1正則化 L2正則化 別名(回帰の場合) ラッソ回帰 (Lasso) リッジ回帰 (Ridge) ペナルティの計算 重みの絶対値の和 重みの二乗の和 結果の特徴 一部の重みが0になる(スパース性) 重みが全体的に小さくなる(0にはならない) イメージ 断捨離(不要なものを捨てる) バランス(突出を抑える)
ひっかけ対策
- 「L1正則化はすべての重みを均一になだらかに小さくする」という記述は誤り(それはL2の特徴)。L1は「ゼロ」にする力が強いです。


📚 より詳細を学びたい方へ

