

勾配消失問題 (Vanishing Gradient Problem)
解説:伝わらない「伝言ゲーム」
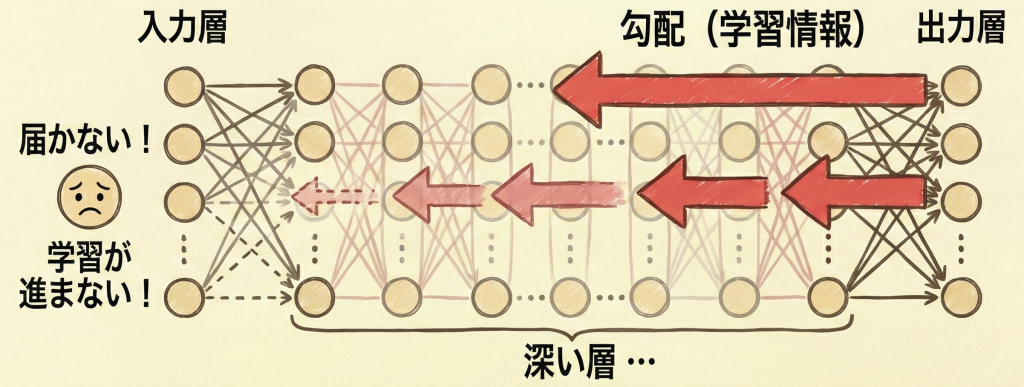
勾配消失問題とは、ディープラーニングにおいて層を深くしすぎると、誤差逆伝播法で学習させる際に、「入力層に近い層(手前の層)ほど、学習が全く進まなくなる」という現象です。
原因:1より小さい数の掛け算
原因は、活性化関数の「微分の性質」にあります。
逆伝播では「微分値を掛け算」しながら進みますが、「1より小さい数」を何度も掛け算すると、値は限りなく0に近づいてしまうため、手前の層に届く頃には情報が消えてしまいます。
「tanh関数」では解決できないのか?
シグモイド関数(微分最大値 0.25)の改良版として、微分最大値が「1.0」になるtanh関数があります。
「最大値が1なら減衰しないのでは?」と思われがちですが、tanh関数でも勾配消失は解決しません。
- 理由:微分値が「1」になるのは入力がちょうど0の時だけで、それ以外では「1未満」になるからです。層が深くなれば、結局は掛け算の連鎖で勾配は消えてしまいます。
救世主:ReLU関数
そこで登場したのが「ReLU関数」です。
ReLUは、入力がプラスであれば「微分値が常に1」です。「1」は何回掛けても「1」のままなので、どれだけ層を深くしても勾配が消失せず、入力層までしっかり届きます。
| 対策アプローチ | 具体的な手法(G検定キーワード) |
|---|---|
| 活性化関数の変更 | ReLU関数を使う。 (正の領域なら勾配が「1」のまま減衰しないため、最も効果的な解決策) |
| 重みの初期値 |
※初期値を工夫して、勾配が消えにくい範囲にデータを収める。 |
| 学習テクニック | バッチ正規化 (Batch Normalization) (層ごとにデータの偏りを整えて、勾配が伝わりやすい状態を保つ) |
G検定対策
出題ポイント
- 発生場所:出力層から遠い「入力層に近い層」ほど、勾配が消失しやすく、パラメータが更新されなくなる。
- 原因と対策:
- シグモイド関数・tanh関数 → 勾配消失が起きやすい。
- ReLU関数 → 勾配消失を回避できる(現在のスタンダード)。
- セット暗記:「シグモイドにはXavier」「ReLUにはHe」の組み合わせは絶対暗記。
よくあるひっかけ問題
- × tanh関数を使えば、微分値が最大1なので勾配消失問題は完全に解決する
(解説)解決しません。シグモイドよりはマシですが、多層化するとやはり消失します。解決するのはReLUです。 - × 勾配消失問題は、出力層に近い層ほど発生しやすい
(解説)逆です。誤差逆伝播は出力層からスタートするため、出力層付近は正常です。伝言が進んだ先(入力層付近)で情報が消えます。

📚 より詳細を学びたい方へ

