

REINFORCE (Monte Carlo Policy Gradient)
解説
REINFORCEとは、方策勾配法の中でも最も基礎的なアルゴリズムで、「モンテカルロ法」ベースの学習手法です。
「テストが終わってから、まとめて見直す」
REINFORCEの最大の特徴は、学習(パラメータ更新)のタイミングです。
- TD法(Q学習・Actor-Criticなど):
「1問解くごとに答え合わせ」をして、即座に反省・修正します。 - REINFORCE(モンテカルロ法):
「テストを最後まで解き終わって点数が出てから」、まとめて「あの時の回答は良かった/悪かった」と振り返ります。
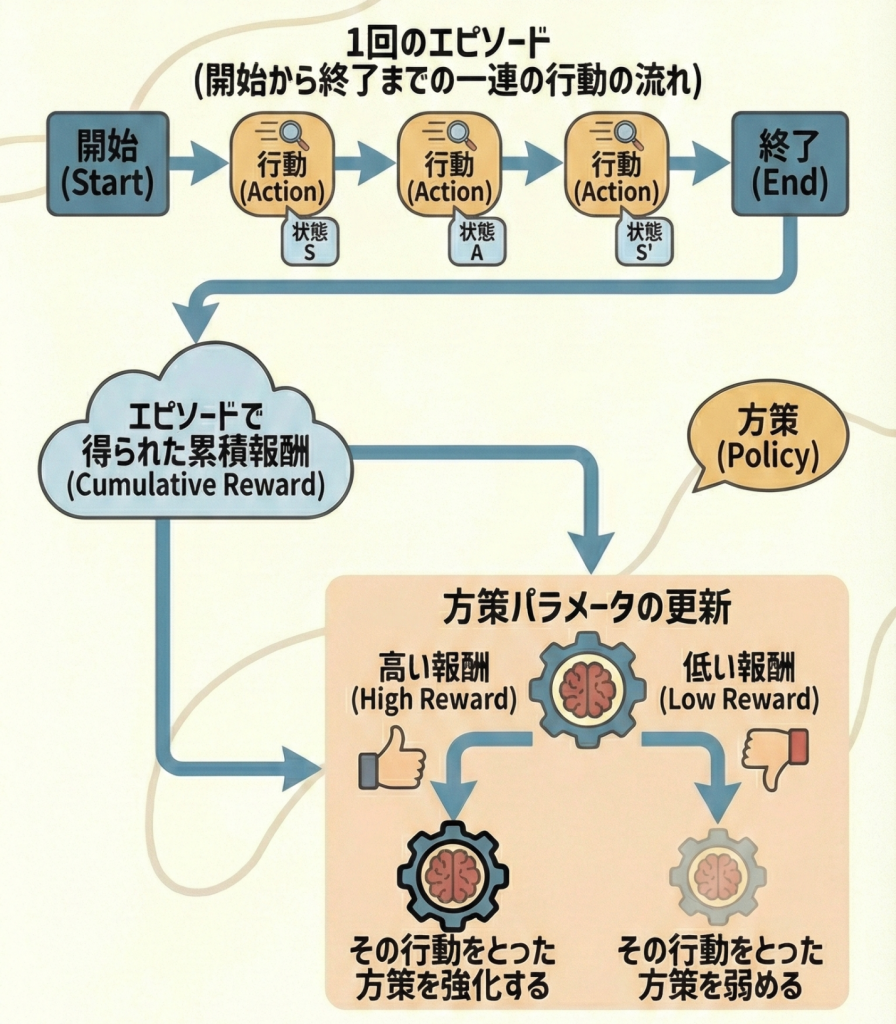
つまり、ゲーム開始から終了(エピソード完了)までを一通り行い、最終的に得られた「総報酬(収益)」を使って、その一連の行動が良かったかどうかを判断し、方策を更新します。
メリットとデメリット
- メリット:価値関数(Critic)を学習する必要がなく、仕組みがシンプル(方策 π だけを学習する)。
- デメリット:エピソードが終わるまで学習が進まないため時間がかかる。また、たまたま運良く勝ったり負けたりする要素(ノイズ)の影響をモロに受けるため、学習のばらつき(分散)が大きい。
G検定対策
出題ポイント
- 分類:「モデルフリー」な「方策勾配法」である。
- 手法:「モンテカルロ法」を用いるため、エピソードが終了するまでパラメータの更新が行われない。
- 構成:基本的には「方策(Policy)」のみをニューラルネットワークで近似し、価値関数は作らない。(※分散を減らすためにベースラインとして価値関数を使う工夫もあるが、基本形は方策のみ)。
よくあるひっかけ問題
- × REINFORCEは、1ステップごとに行動した直後に学習を行う(TD法)
(解説)違います。エピソード終了後に行うのがモンテカルロ法(REINFORCE)の特徴です。逐次行うのはActor-Criticなどです。 - × Actor-Criticの一種である
(解説)REINFORCEはActor(方策)だけで学習します。Critic(価値関数)による評価を行わないため、Actor-Criticではありません。


📚 より詳細を学びたい方へ

