

Q学習 (Q-learning)
解説
Q学習(Q-learning)は、強化学習において最も代表的な手法の一つです。
「ある状態で、ある行動をとったときに、将来どれくらいの報酬が得られるか」を表す値、すなわち「行動価値関数 Q(s, a)」を学習します。
「Qテーブル」の更新
Q学習では、縦軸に「状態(State)」、横軸に「行動(Action)」をとった表(Qテーブル)を作り、実際に動き回りながら、より良い結果が出た行動の点数(Q値)を書き換えていきます。
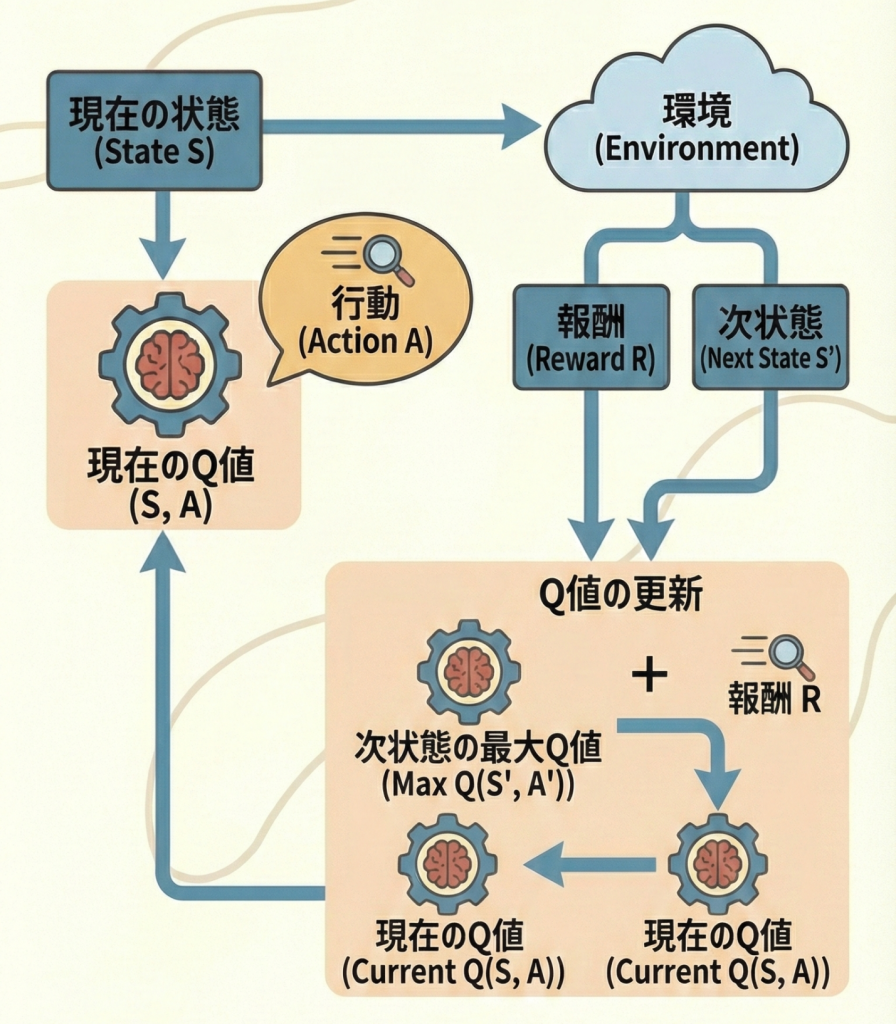
最大の特徴:Off-policy(オフ方策)
Q学習の最大の特徴は、Q値を更新する際に「次の状態でとりうる『最大(max)』のQ値を使う」という点です。
実際に次のステップでその行動をとるかどうかに関わらず、「もしベストを尽くしたらこれくらい貰えるはず」という理想値を使って現在の評価を更新します。これをOff-policy(オフ方策)型と呼びます。
ライバル「SARSA」との違い
G検定では、Q学習と非常によく似た手法である「SARSA(サーサ)」との比較が頻出です。最大の違いは、「次の行動をどう見積もるか(理想か現実か)」という点にあります。
| 比較項目 | Q学習 (Q-learning) | SARSA (サーサ) |
|---|---|---|
| 学習タイプ | Off-policy(オフ方策) | On-policy(オン方策) |
| 更新の基準 | 次の状態で最大のQ値を使う。 (理想的な行動を仮定) |
実際に次の状態で選んだ行動のQ値を使う。 (現実の行動を反映) |
| 性格・特徴 | 「楽観的」 探索中に悪い行動をとっても「次は最善の手を打つはず」と仮定して学習するため、最短経路(最適解)を見つけやすいが、リスクを負うこともある。 |
「堅実・慎重」 探索中にあえて選んだ(あるいは失敗した)行動の結果も学習に反映するため、崖っぷちを歩くような危険なルートを避け、安全な方策になりやすい。 |
G検定対策
出題ポイント
- 定義:「行動価値関数 Q(s, a)」を学習する「モデルフリー」の手法である。
- 更新式:数式の中に max Q(s’, a’) (次の状態での最大値)が含まれていればQ学習である。
- 用語:「Off-policy(オフ方策)」手法の代表例として名前が挙がる。
ひっかけ対策・注意点
- × SARSAとの混同:
「実際に選択した行動を使って更新する」のはSARSA、「最大のQ値を使って更新する」のがQ学習です。 - Qテーブルの限界:
状態や行動の数が少なければ「表(テーブル)」で管理できますが、囲碁や自動運転のように状態が無限にある場合はテーブルが作れません。そのため、Q関数をディープラーニング(ニューラルネットワーク)で近似するDQN(Deep Q-Network)へと発展します。


📚 より詳細を学びたい方へ

