

t-SNE (t-Distributed Stochastic Neighbor Embedding)
解説
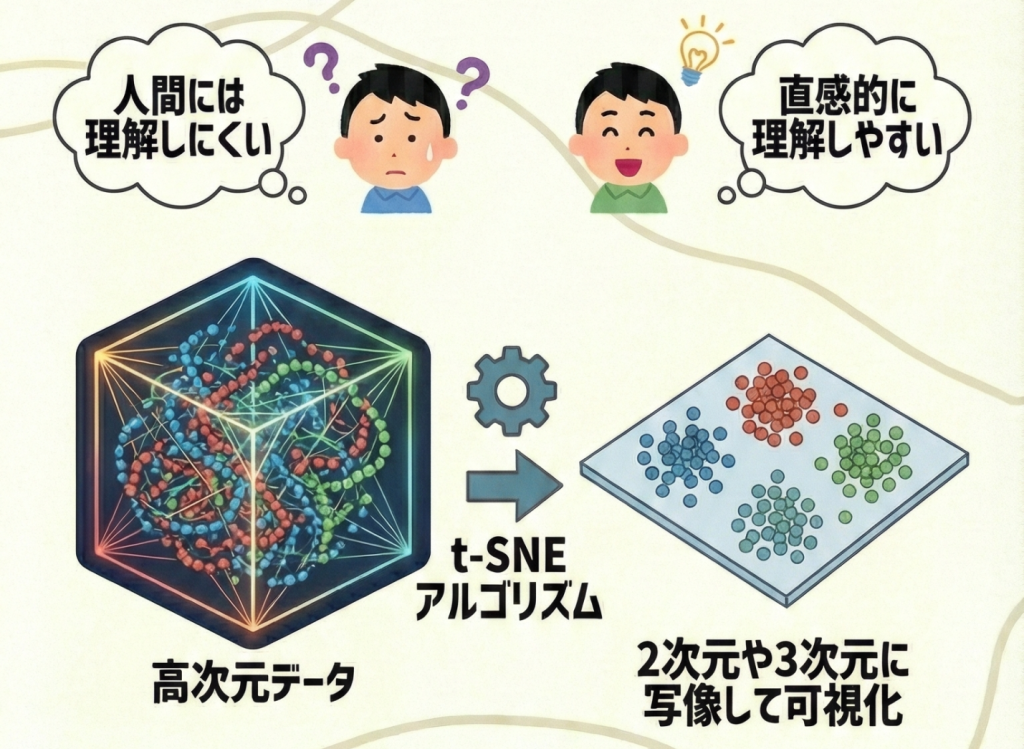
t-SNE(ティー・スニー)とは、高次元データを2次元や3次元に圧縮し、人間が目で見て分かるように可視化するための「非線形」な次元削減手法です。
「近くのものは近くに」
主成分分析(PCA)が「全体のばらつき(分散)」を重視するのに対し、t-SNEは「データ間の局所的な関係(近さ)」を重視します。
高次元空間で「近くにいるデータ同士」は、低次元空間(2次元など)に移しても「近く」になるように、逆に「遠くにあるデータ」は「遠く」になるように配置します。
確率分布とt分布
この手法の面白い点は、距離を「確率」に変換して扱うことです。
- SNE(Stochastic Neighbor Embedding):高次元での距離関係を確率分布(ガウス分布)で表現します。
- t-SNE:低次元側の確率分布に「t分布(裾の重い分布)」を使います。これにより、データが中心にギュッと集まりすぎてしまう問題(混雑問題)を解消し、クラスタ(グループ)を綺麗に分離して表示できます。
PCAとの違い
| 比較項目 | PCA (主成分分析) | t-SNE |
|---|---|---|
| 手法 | 線形 | 非線形 |
| 重視する点 | 全体的な構造(分散最大化) | 局所的な構造(近傍関係) |
| 再現性 | 毎回同じ結果になる | 計算ごとに結果が変わる(確率的) |
G検定対策
出題ポイント
- 目的:高次元データの構造を理解するための「可視化(Visualization)」に特化した手法である。
- 特徴:「非線形」な手法であり、複雑な形状のデータ(スイスロールなど)も綺麗に展開できる。
- キーワード:「局所的な構造の保持」、「t分布(混雑問題の解消)」。
よくあるひっかけ問題
- × t-SNEの結果の軸(横軸・縦軸)には、PCAのように明確な意味がある
(解説)ありません。t-SNEは距離関係だけを保つように配置するため、座標軸の数値自体には意味がなく、解釈はできません(「右に行くほど年収が高い」などは言えない)。 - × 新しいデータに対しても、学習済みt-SNEモデルを使って簡単に次元圧縮できる
(解説)できません。t-SNEは「今あるデータ」を配置することに特化しており、未知のデータを追加して変換する機能(写像関数)は持ちません。


📚 より詳細を学びたい方へ

