

ブースティング (Boosting)
解説
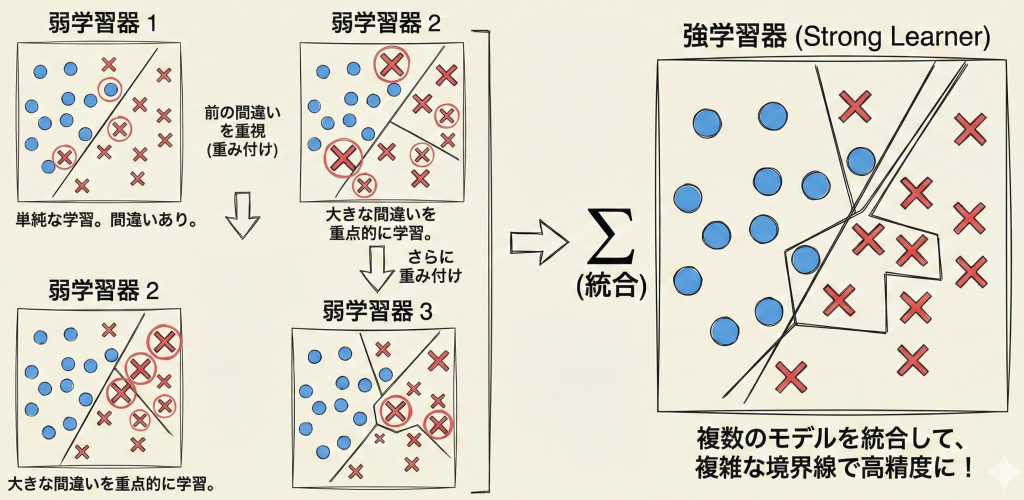
ブースティングとは、アンサンブル学習(複数のモデルを組み合わせる手法)の一つで、複数の「弱学習器(Weak Learner)」を「逐次的(直列)」に学習させ、前のモデルの失敗を次のモデルが修正していくことで、最終的に非常に精度の高い「強学習器」を作る手法です。
バケツリレー方式の学習
バギング(ランダムフォレスト)が「みんなで一斉に投票する(並列)」のに対し、ブースティングは「前の人が間違えた問題を、次の人が重点的に解く(直列)」というバケツリレーのような仕組みです。
学習のプロセス
- 最初の弱学習器(モデル1)が予測を行う。
- モデル1が間違えた(誤差が大きい)データを特定する。
- 間違えたデータの「重み」を増やしたり、その「誤差(残差)」そのものを予測対象にしたりして、次の弱学習器(モデル2)を学習させる。
- これを繰り返し、最後にすべてのモデルを重み付きで合体させる。
代表的なアルゴリズム
| AdaBoost (エイダブースト) |
間違えたデータの「重み」を更新して、次のモデルがそのデータを重視するように学習する手法。初期の代表的なアルゴリズム。 |
| 勾配ブースティング (GBDT) |
前のモデルの「残差(正解とのズレ)」を、次のモデルが予測するように学習する手法。現在の主流。 ※発展形としてXGBoost, LightGBM, CatBoostがある。 |
G検定対策
出題ポイント
- バイアスの低減:ブースティングは、モデルの適合不足を解消していくため、「バイアス(偏り)」を下げる効果が高い。(対してバギングは「バリアンス(分散)」を下げる)。
- 弱学習器:個々のモデルには、少しだけランダムより賢い程度の単純なモデル(深さの浅い決定木など)が使われる。これを「Decision Stump」と呼ぶこともある。
よくあるひっかけ問題
- × ブースティングは、並列処理によって高速に学習できる
(解説)これは「ランダムフォレスト(バギング)」の特徴です。ブースティングは前の結果を待たないといけないため、基本的には「直列処理」であり、学習に時間がかかります。 - × ノイズの多いデータに対して非常に強い
(解説)逆です。ブースティングは「間違えたデータ(ノイズ)」に過剰に適合しようとするため、ノイズが多いと過学習しやすい傾向があります。

📚 より詳細を学びたい方へ

