

決定木(Decision Tree)
1. 解説
決定木は、「もし〇〇ならA、そうでなければB」という条件分岐を繰り返し、フローチャートのような木構造を作って予測を行う機械学習モデルです。
分類問題(分類木)と回帰問題(回帰木)の両方に利用できます。最大の特徴は、人間にとって「なぜその予測結果になったのか」という理由が非常に分かりやすい(解釈性が高い)点です。これを「ホワイトボックスなモデル」と呼びます。
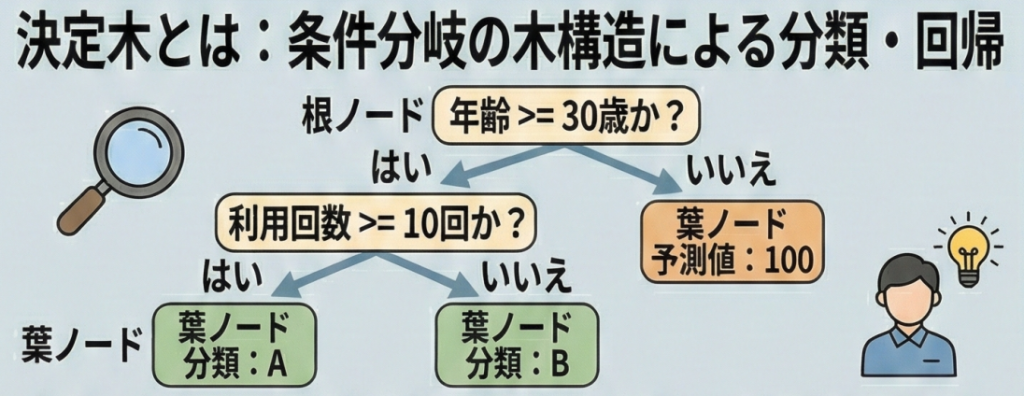
仕組み:どうやって木を分けるのか?
決定木は、適当に分岐しているわけではありません。データを分けた後に「中身ができるだけ綺麗に(同じクラスばかりに)なるように」分割します。
- 不純度(Impurity):データの中に異なるクラスがどれくらい混ざっているかを表す指標。
- ジニ係数(Gini Impurity)
- エントロピー(Entropy)
- 情報利得(Information Gain):分岐することによって、どれだけ不純度が減ったか(綺麗になったか)を表す値。
決定木は、この「情報利得」が最大になるような質問(分岐条件)を自動で探して学習します。
メリットとデメリット(弱点)
G検定では、この「弱点」とその「対策」がセットで出題されます。
| 項目 | 内容 | 対策手法 |
|---|---|---|
| メリット | 解釈性が高い (予測の根拠を人間に説明できる) データの前処理があまり要らない。 |
― |
| デメリット | 過学習しやすい (木が深くなると、訓練データだけに適合しすぎる) |
① 剪定(Pruning): 不要な枝を切って木を単純にする。 ② アンサンブル学習: ランダムフォレストなどで複数の木を使う。 |
2. G検定対策
出題ポイント
- 用語の定義:「ノード(節)」、「エッジ(枝)」、「リーフ(葉)」といった木構造の用語。
- 不純度の指標:分類木では「ジニ係数」や「エントロピー」が使われ、これらが小さくなるように分割が進む。
- ホワイトボックス性:ディープラーニングのような「ブラックボックス」とは対照的に、中身が理解しやすいモデルであること。
ひっかけ対策・注意点
- × 決定境界は斜めに引ける
(解説)基本的な決定木は、軸(X軸やY軸)に対して垂直・水平にしか境界線を引けません。そのため、斜めの境界が必要なデータでは階段状(ギザギザ)の境界線になります。 - アンサンブル学習との関係:
決定木単体では過学習しやすいため、実務では「ランダムフォレスト」や「勾配ブースティング(GBDT)」などの、決定木をたくさん集めて強化したモデルがよく使われます。これらは精度が高い反面、単体の決定木よりも解釈性は下がります。


📚 より詳細を学びたい方へ

