

機械学習(Machine Learning)
1. 解説
機械学習とは、データから反復的に学習し、そこに潜むパターンや規則性を見つけ出す技術です。人間が「この場合はこうする」というルールを全て記述するのではなく、コンピュータ自身がデータからルール(モデル)を構築するのが特徴です。
G検定において最も重要なのは、機械学習が大きく「教師あり学習」「教師なし学習」「強化学習」の3つに分類される点と、それぞれの使い分けを理解することです。
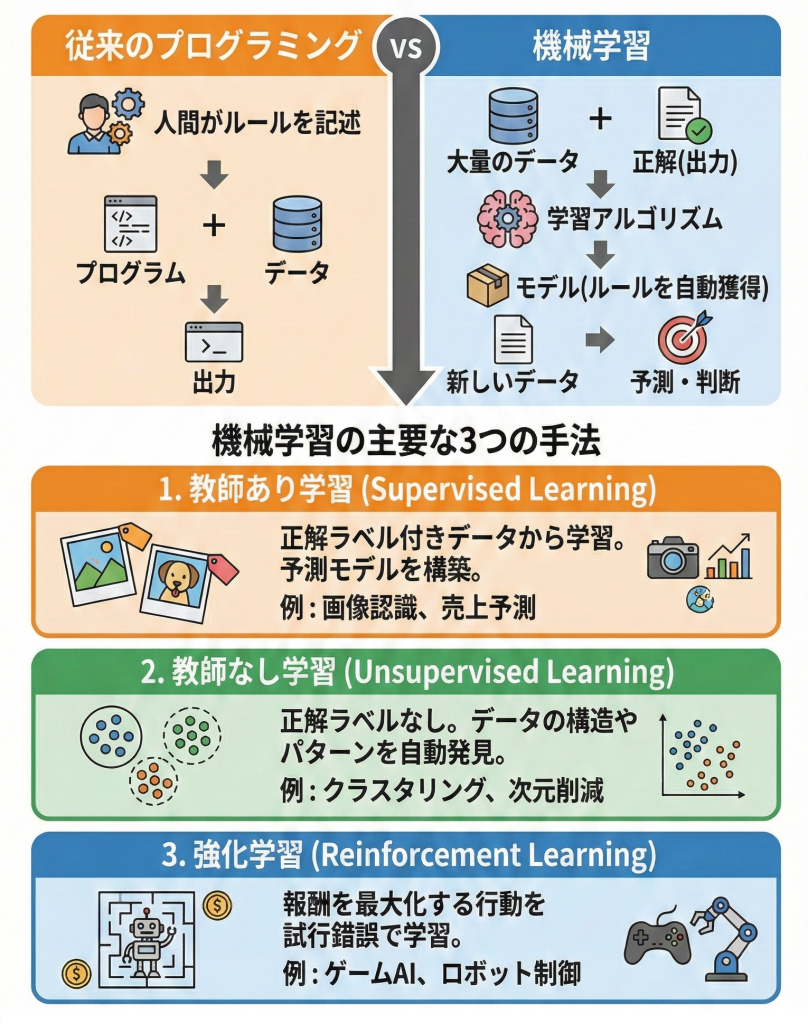
機械学習の3大分類
学習データの与え方と目的によって、以下の3つに分けられます。
| 分類 | データの形式 | 目的・タスク | 具体例 |
|---|---|---|---|
| ① 教師あり学習 (Supervised) |
入力データ + 正解ラベル (問題と答えのセット) |
正解を予測する ・回帰(数値予測) ・分類(クラス分け) |
・明日の気温予測(回帰) ・スパムメール判定(分類) |
| ② 教師なし学習 (Unsupervised) |
入力データのみ (正解ラベルなし) |
データの構造や特徴を知る ・クラスタリング ・次元削減 |
・顧客のグルーピング ・異常検知(外れ値発見) |
| ③ 強化学習 (Reinforcement) |
行動と報酬 (環境からのフィードバック) |
報酬を最大化する行動ルールを獲得する | ・将棋や囲碁のAI ・ロボットの歩行制御 |
重要なキーワード:特徴量(Feature)
機械学習において、データのどの部分に着目するかを表す変数を「特徴量」と呼びます。
従来の機械学習(第2次AIブーム)では、人間が専門知識を使って「どの特徴量を使うか」を設計する必要がありました。これを特徴量エンジニアリングと言います。
(※ここが、特徴量を自動で抽出できるディープラーニングとの最大の違いです)
2. G検定対策
出題ポイント
- 回帰と分類の違い:
- 回帰(Regression):連続する「数値」を予測する(例:明日の株価、家賃の価格)。
- 分類(Classification):「カテゴリ」を予測する(例:犬か猫か、合格か不合格か)。
- 過学習(Overfitting):学習データに適合しすぎて、未知のデータに対して精度が落ちてしまう状態。これを防ぐ能力を汎化性能と呼ぶ。
- 教師なし学習の手法:「k-means法(クラスタリング)」や「主成分分析(次元削減)」などの名称が出題されやすい。
ひっかけ対策・注意点
- × 強化学習 = 教師なし学習の一種
(解説)別物です。強化学習は「報酬」というフィードバックがあるため、純粋な教師なし学習とは区別されます。 - × 機械学習はデータを入れれば勝手に賢くなる
(解説)従来の機械学習では、データをそのまま使うのではなく、人間による適切な前処理や特徴量の設計が不可欠です。 - 教師あり学習の「正解データ」:「教師データ」「ラベル」「ターゲット」などと呼ばれることもありますが、同じ意味です。


📚 より詳細を学びたい方へ

