

統計的機械翻訳(SMT)
解説
統計的機械翻訳(SMT:Statistical Machine Translation)とは、1990年代から2010年代半ばにかけて主流だった翻訳手法です。IBMの研究チームなどが提唱し、それまでの「ルールベース機械翻訳(RBMT)」から、「データに基づく確率論的な翻訳」へとパラダイムシフトを起こしました。
翻訳の仕組み(確率モデル)
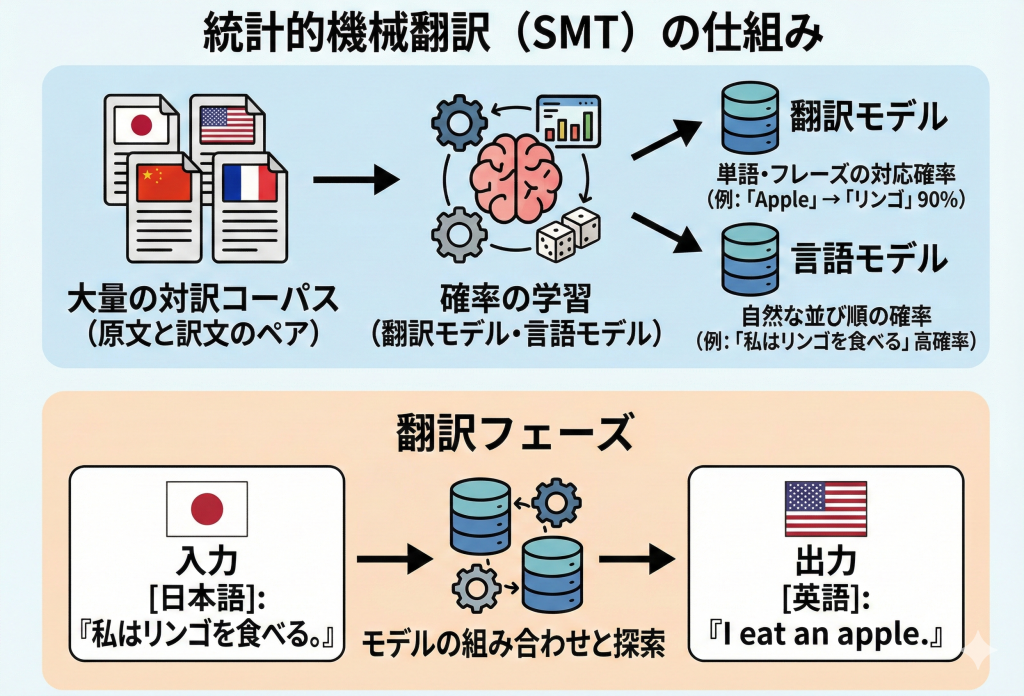
SMTは、大量の「原文と訳文のペア(対訳コーパス)」をコンピュータに読み込ませ、単語やフレーズがどのように翻訳されるかの「確率」を学習します。
- 翻訳モデル:ある単語が別の言語のどの単語に対応するかの確率(例:「Apple」が「リンゴ」になる確率は90%)。
- 言語モデル:その並び順が、ターゲット言語として自然かどうかの確率(例:「私は食べるリンゴを」より「私はリンゴを食べる」の方が高確率)。
この2つのモデルを組み合わせることで、最も確からしい訳文を出力します。
限界とNMTへの移行
SMTは辞書を手作りする必要がないため画期的でしたが、単語や短いフレーズ単位で切り取って処理するため、「語順が大きく異なる言語(日米など)に弱い」「文脈を考慮できず、長文が不自然になる」という限界がありました。これを解決したのが、現在の主流であるニューラル機械翻訳(NMT)です。
G検定対策
出題ポイント
- キーワード:対訳コーパス(パラレルコーパス)、IBMモデル、フレーズベース翻訳(PBMT)。
- 歴史的変遷:「ルールベース(RBMT)」→「統計的(SMT)」→「ニューラル(NMT)」という進化の真ん中に位置する技術。
- 特徴:「翻訳モデル」と「言語モデル」の積で確率を計算するアプローチ。
よくあるひっかけ問題
- × 文法ルールを人間が手作業で入力する
(解説)これは「ルールベース機械翻訳(RBMT)」の特徴です。SMTはデータから確率を学習します。 - × ディープラーニングを用いて文脈を理解する
(解説)これは「ニューラル機械翻訳(NMT)」の特徴です。SMTはあくまで統計的な確率計算であり、文脈の意味理解(ベクトル化)までは行いません。
