

教師なし学習 (Unsupervised Learning)
解説
教師なし学習とは、入力データのみをコンピュータに与え、正解データ(教師データ)を与えずに、データそのものが持つ構造や特徴を学習させる手法です。
「答え」のない学習
教師あり学習が「ドリル(問題と答え)」で学ぶのに対し、教師なし学習は「ひたすら観察して法則を見つける」学習です。
例えば、大量の動物の画像をAIに見せたとき、「これは猫」「これは犬」という正解は教えませんが、AI自身が「耳が尖っているグループ」「鼻が長いグループ」といった特徴を見つけ出し、自動的にグループ分けを行います。
主なタスク:クラスタリングと次元削減
教師なし学習の代表的な用途は以下の2つです。
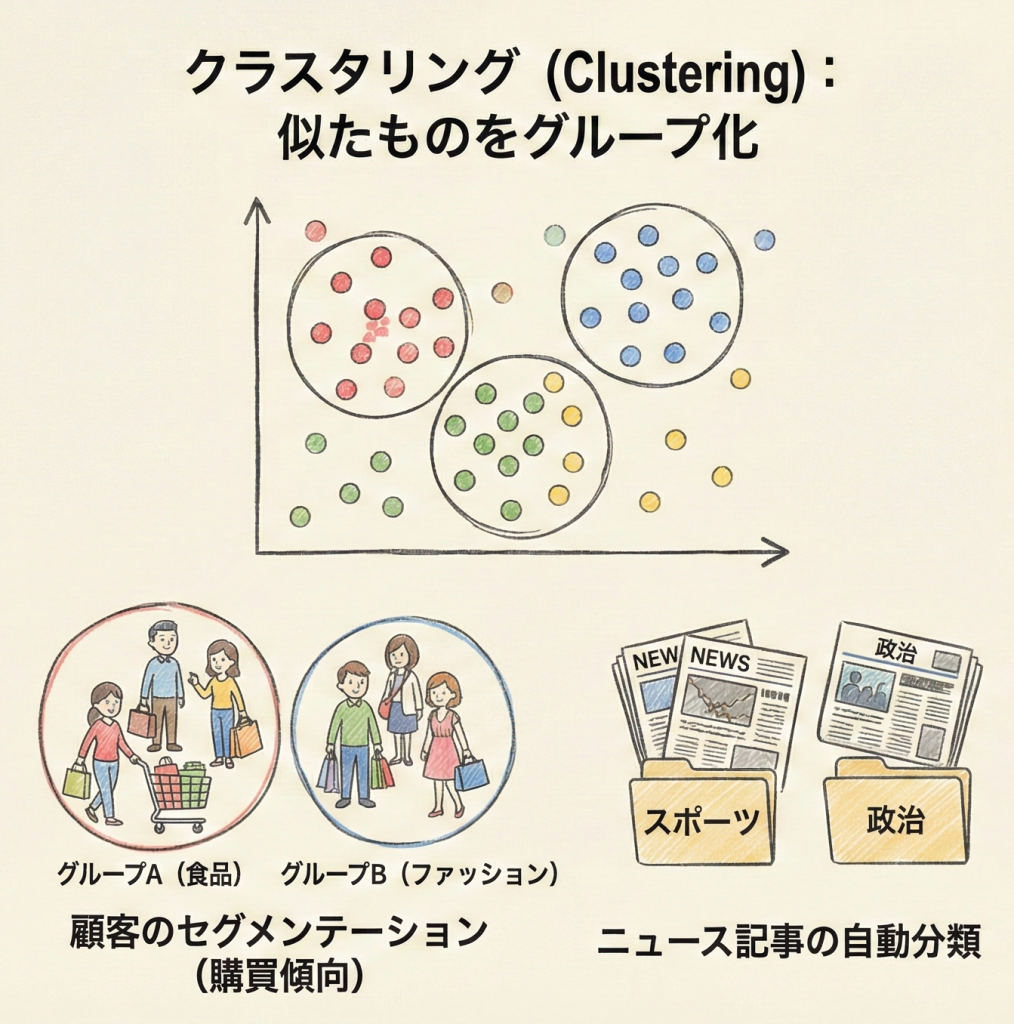
- クラスタリング(Clustering):
データを似たもの同士のグループ(クラスタ)に分ける手法。例:顧客データのセグメンテーション(購買傾向が似ている客をまとめる)、ニュース記事の自動分類など。
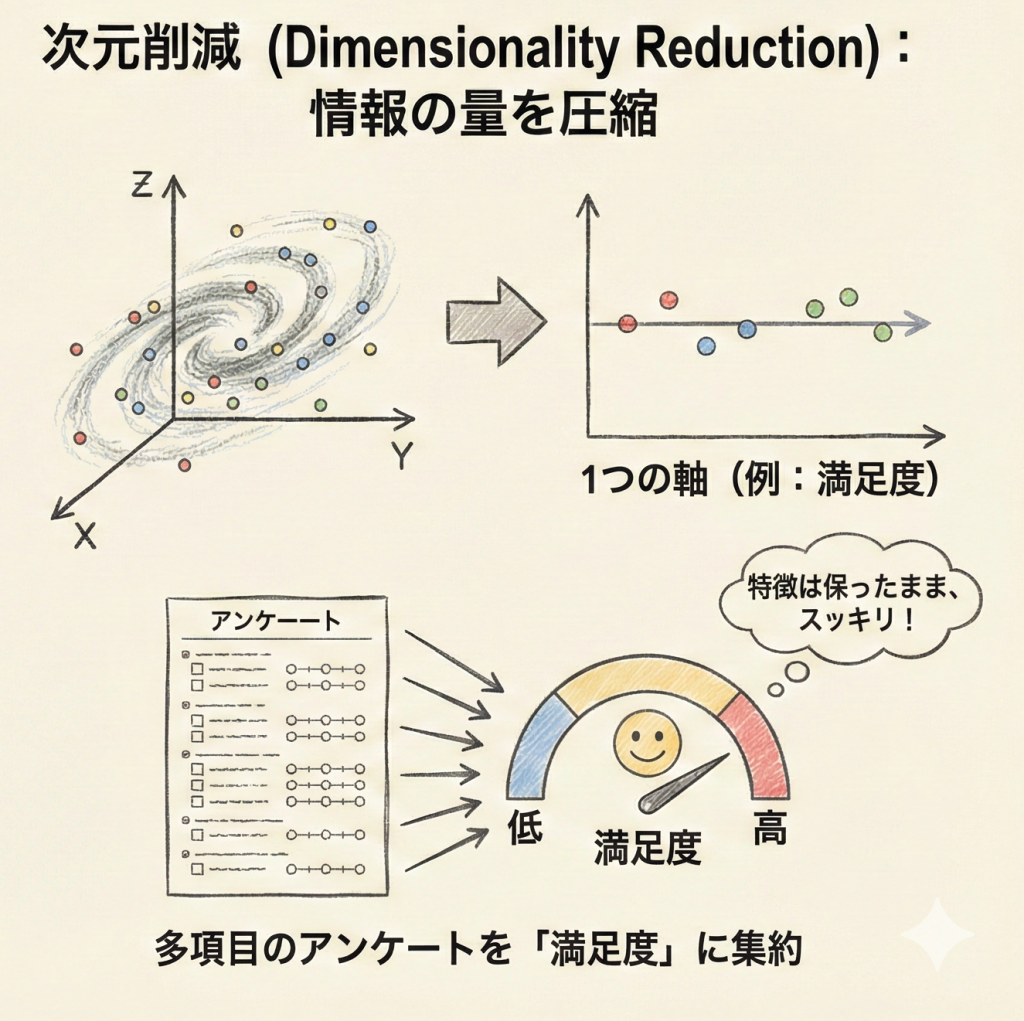
- 次元削減(Dimensionality Reduction):
データの特徴を保ったまま、情報の量(次元数)を減らす手法。例:多項目のアンケート結果を「満足度」という1つの軸にまとめる(主成分分析など)。
G検定対策
出題ポイント
- 定義:「入力データ」のみを与え、「正解ラベル」を与えないこと。
- 代表的手法:
- k-means法(k平均法):データをk個のグループに分けるクラスタリング手法。
- 主成分分析(PCA):データを要約する次元削減手法。
- アソシエーション分析:「おむつとビール」のようなルールを見つける手法。
- 活用例:異常検知(通常データとは異なる外れ値を見つける)、レコメンデーション。
よくあるひっかけ問題
- × クラスタリングは、分類タスク(教師あり学習)の一種である
(解説)これが最も頻出のひっかけです。- 分類(Classification):「犬か猫か」を当てる(答えがある=教師あり)。
- クラスタリング(Clustering):「似たもの同士」を集める(答えがない=教師なし)。
この2つの用語の違いは必ず区別してください。
- × k-means法は、正解ラベルを用いて学習する
(解説)k-means法は教師なし学習なので、正解ラベルは使いません。
