

蒸留 (Knowledge Distillation)
解説:名教師の「暗黙知」を受け継ぐ
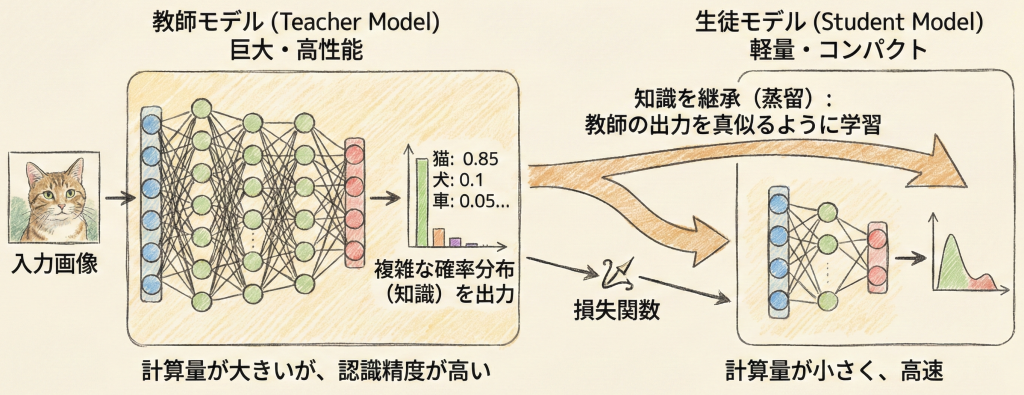
蒸留(知識蒸留)は、性能は高いが計算量が巨大な「教師モデル(Teacher Model)」の知識を、軽量でコンパクトな「生徒モデル(Student Model)」にコピーして継承させる学習手法です。
生徒モデルは、単に「正解(犬か猫か)」を教わるだけでなく、教師モデルが弾き出した「推論の過程(確率の迷い具合)」まで真似するように学習します。
これにより、パラメータ数が少ない生徒モデルでも、教師に近い精度を出せるようになります。
💡 なぜ「答え」だけじゃダメなの?
例えば、「ゴールデンレトリバー」の写真を見せたとします。
例えば、「ゴールデンレトリバー」の写真を見せたとします。
- 正解データ(Hard Target):
「これは犬だ! 猫の可能性はゼロ!」(0か1か)
→ 情報量が少なく、ヒントが単純すぎる。 - 教師モデルの出力(Soft Target):
「90%は犬だけど、耳の形が少し猫っぽいから9%くらい猫の要素もある。でも車である確率は1%以下だね」
→ 「何と何が似ているか」という豊かな情報(暗黙知)が含まれている。
生徒モデルはこの「猫っぽい要素もある」というソフトな情報(確率分布)も一緒に学ぶことで、単なる丸暗記よりも深く特徴を理解できるのです。
学習の仕組み
生徒モデルは、以下の2つの損失(Loss)を同時に最小化するように学習します。
- Hard Target(正解ラベル)との誤差: 本当の正解と合っているか。
- Soft Target(教師の出力)との誤差: 教師の「思考のクセ(確率分布)」と似ているか。
| 用語 | 意味と役割 |
|---|---|
| 教師モデル (Teacher) |
事前学習済みの巨大モデル。精度は最高だが、重すぎて実用(エッジなど)には向かない。 |
| 生徒モデル (Student) |
これから学習する軽量モデル。教師の知識を吸収して、軽さと賢さの両立を目指す。 |
| 温度付きSoftmax (Temperature) |
教師の出力をより滑らか(Soft)にするためのパラメータ $T$。これを調整して「暗黙知」を抽出しやすくする。 |
G検定対策
出題ポイント
- 目的:モデルの「軽量化(圧縮)」と「精度の維持」。エッジAIなどで使われる。
- キーワード:「教師モデル(Teacher)」「生徒モデル(Student)」「Soft Target(確率分布)」「Hard Target(One-hotベクトル)」。
- 効果:ゼロから生徒モデルを学習させるよりも、蒸留を使ったほうが精度が高くなる傾向がある。
ひっかけ対策
- × 生徒モデルは教師モデルよりも精度が高くなる
(解説)目標は「教師に近づくこと」なので、基本的には教師の劣化コピー(近似)になります。「教師より軽くなったのに、精度はあまり落ちていない」が成功ラインです。(※稀に教師を超えることもありますが、試験的な正解は『教師の精度に近づける』です) - × 蒸留はデータ拡張(Data Augmentation)の一種である
(解説)蒸留は「モデル圧縮・学習手法」の一種です。データを増やす技術ではありません。
