マルチモーダルAI:視覚とコトバを繋ぐ技術の最前線
解説:「目」と「耳」を同時に持つAI
人間は、目で見た情報(視覚)と、耳で聞いた言葉(言語)を脳内で瞬時に結びつけて世界を理解しています。「マルチモーダルAI」とは、まさにこの人間のように、画像、テキスト、音声など、種類の異なる複数のデータ(モダリティ)を組み合わせて処理するAI技術の総称です。
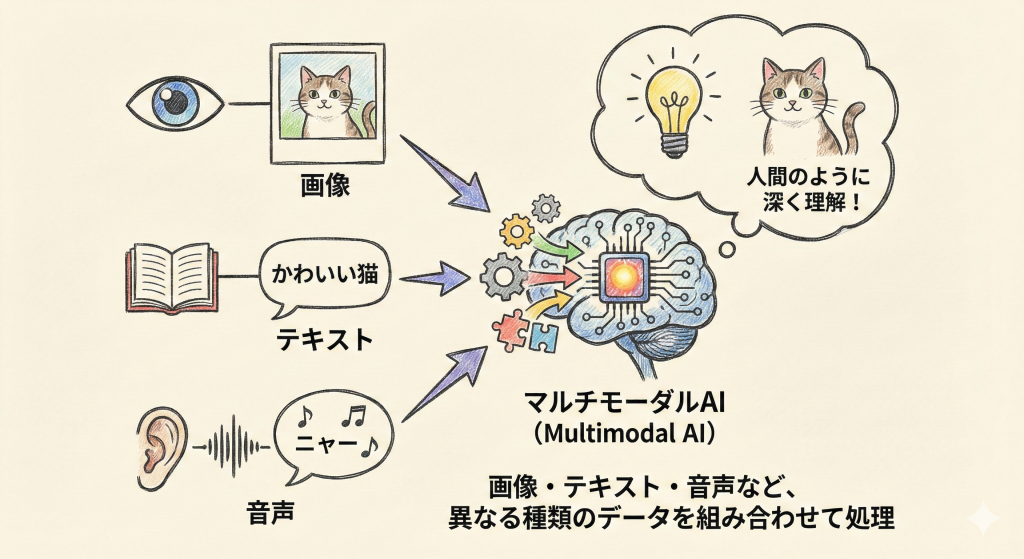
これまでのAIは「画像認識だけ」「翻訳だけ」といったシングルモーダルな処理が中心でした。しかし、異なる情報を統合することで、AIはより深く、柔軟に世界を認識できるようになります。
1. マルチモーダルAIの主要タスク
マルチモーダル技術によって実現する具体的なタスク(何ができるか)を紹介します。これらは、後述する巨大なモデルたちの基礎能力となっています。
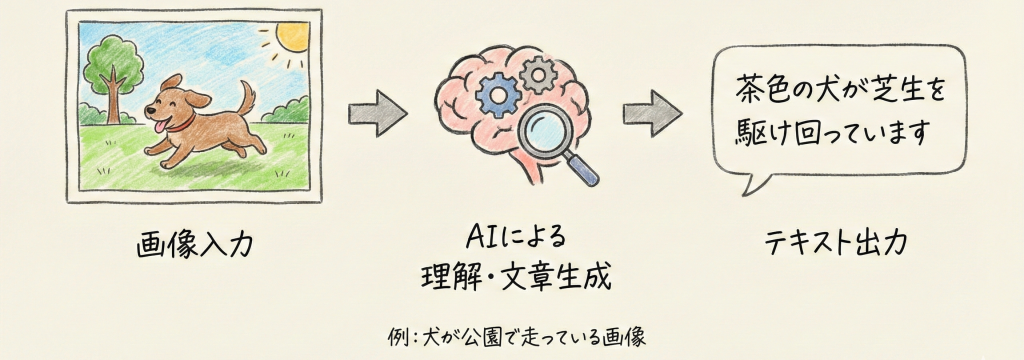
Image Captioning(画像キャプション生成)
「画像→テキスト」のタスクです。入力された画像の内容を理解し、それを説明する適切な文章を生成します。(例:犬が公園で走っている画像を見て、「茶色の犬が芝生を駆け回っています」と出力する)
Visual Question Answering (VQA:視覚的質問応答)
「画像+テキスト(質問)→テキスト(回答)」のタスクです。画像に関する質問をテキストで投げかけ、AIに答えさせます。(例:冷蔵庫の中の写真を見せて「牛乳はどこにある?」と聞くと、「一番上の棚の右側です」と答える)
Text-To-Image(テキストからの画像生成)
「テキスト→画像」のタスクです。近年、最も注目を集めている分野で、「宇宙飛行士が馬に乗っている写真」のようなテキスト指示(プロンプト)から、リアルな画像を生成します。「Stable Diffusion」や「Midjourney」、そして後述する「DALL-E」が代表例です。
2. 技術的ブレイクスルー:基盤モデルとZero-shot
近年のマルチモーダルAIの急速な進化は、以下の2つの概念によって支えられています。
基盤モデル (Foundation Model)
特定のタスク専用ではなく、Web上の膨大な画像とテキストのペアデータなどを用いて、あらかじめ超大規模に訓練された「汎用的なAIモデル」のことです。
この巨大な「土台(基盤)」があることで、少しの調整であらゆるタスクに対応できる高いポテンシャルを持ちます。LLMであるGPTシリーズ(言語)や、後述するCLIP(視覚と言語)がこれにあたります。
Zero-shot (ゼロショット)
基盤モデルが持つ強力な汎化能力により、「そのタスク専用の追加学習(ファインチューニング)を一切行わずに」、初めて見るタスクをこなしてしまう能力のことです。
例えば、犬と猫の種類を一切教えていない(訓練画像を見せていない)状態でも、「これは犬ですか?猫ですか?」と聞くだけで分類できてしまうような能力を指します。
3. 歴史を変えた重要モデルたち
現在のマルチモーダルブームを牽引する、マイルストーンとなったモデルを紹介します。
CLIP (Contrastive Language-Image Pre-training)
OpenAI / 2021年
マルチモーダル時代の扉を開いた革命的なモデルです。Web上の4億ペアもの画像とテキストを使い、「どの画像と、どのテキストが対応しているか(似ているか)」を学習しました(対照学習)。
これにより、AIは「画像とテキストを同じ空間(ベクトル空間)で理解する」能力を獲得し、驚異的なZero-shot画像分類性能を示しました。
CLIP自体は画像を生成しませんが、「テキストと画像がどれくらい合っているか」を正確に判定できるため、多くの画像生成AI(DALL-E 2やStable Diffusionなど)の内部で「評価役」として使われています。
DALL-E (ダル・イー)
OpenAI / 2021年~
Text-To-Image(テキストからの画像生成)ブームの火付け役となったモデルです。CLIPで培われた「言葉と画像の対応関係」の知識を応用し、テキスト入力から創造的で高精細な画像を生成します。進化版のDALL-E 2、DALL-E 3と性能向上を続けています。
Flamingo (フラミンゴ)
DeepMind / 2022年
静止画だけでなく、動画や、複数の画像が交互に現れるような複雑な文脈も理解できる視覚言語モデルです。「この画像とこの画像の違いを説明して」といった高度な対話が可能であり、Few-shot(数枚の例示)で新しいタスクに適応する能力に優れています。
Unified-IO
Allen AI / 2022年
「統一モデル(Unified Model)」のアプローチです。これまで別々のモデルで行っていた「画像生成」「Image Captioning」「VQA」など、数十種類の異なるタスクを、たった1つのモデルで全てこなすことを目指した野心的なモデルです。入出力の形式を統一することでこれを実現しています。
G検定対策
出題ポイント
- 用語の定義:「マルチモーダル」とは複数の種類のデータを組み合わせること。「Text-To-Image」「VQA」などのタスク名と内容が一致するように。
- CLIPの革新性:画像とテキストを同じ特徴空間にマッピングし、高いZero-shot性能を実現した点。
- 基盤モデルの概念:大規模データでの事前学習により、多様なタスクへ応用できる土台となるモデル。
- モデルとタスクの対応:「DALL-Eは画像生成」「CLIPは画像と言語の対応付け」といった基本的な役割を把握する。
ひっかけ対策
- × CLIPは高精細な画像を生成するモデルである
(解説)CLIPは「画像とテキストの類似度を測る」モデルです。画像を生成するのはDALL-Eなどです。(※ただし、画像生成AIの内部でCLIPが使われていることは多いです) - × Zero-shotとは、学習データがゼロという意味である
(解説)事前学習(基盤モデルの作成)には膨大なデータを使っています。「特定のタスク専用の追加学習データがゼロ」という意味です。