

文脈の理解と「ディープラーニング・LLM」へ
word2vecなどの分散表現は画期的でしたが、「多義語(同じ単語でも文脈によって意味が違う)」を区別できないという課題がありました。
文脈(Context)を理解するために発展したニューラルネットワークと、現在のAIブームの火付け役である「Transformer」および大規模言語モデル(LLM)について解説します。
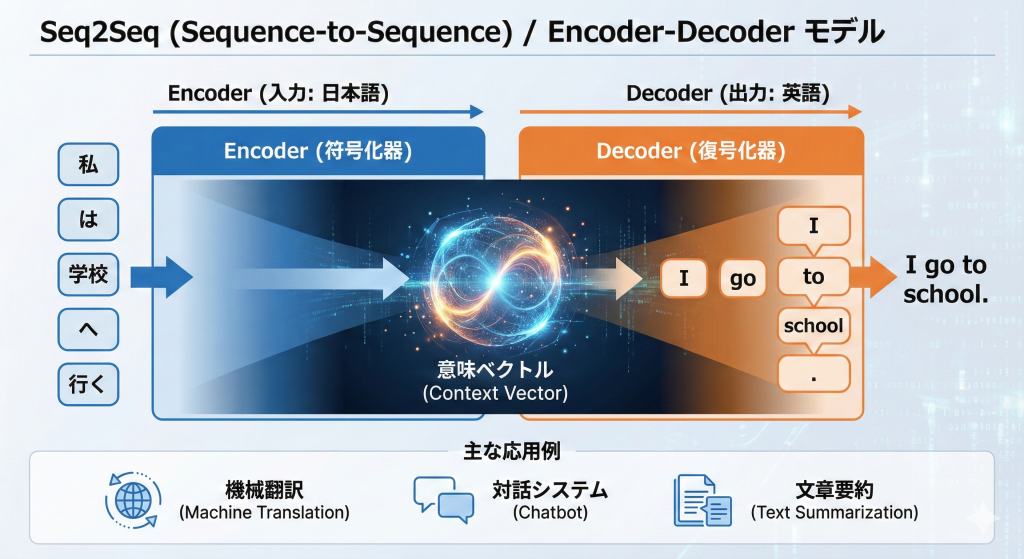
Seq2Seq(Sequence-to-Sequence)
ある時系列データ(文章など)を、別の時系列データに変換するモデルです。「Encoder-Decoderモデル」とも呼ばれます。
- Encoder(入力):日本語の文章を読み込み、意味をベクトルに圧縮する。
- Decoder(出力):そのベクトルをもとに、英語の文章を生成する。
主に機械翻訳、対話システム(チャットボット)、文章要約などで使われます。
CEC(Constant Error Carousel)
これはモデル名ではなく、LSTM(Long Short-Term Memory)というリカレントニューラルネットワーク(RNN)の中にある重要な「部品」の名前です。
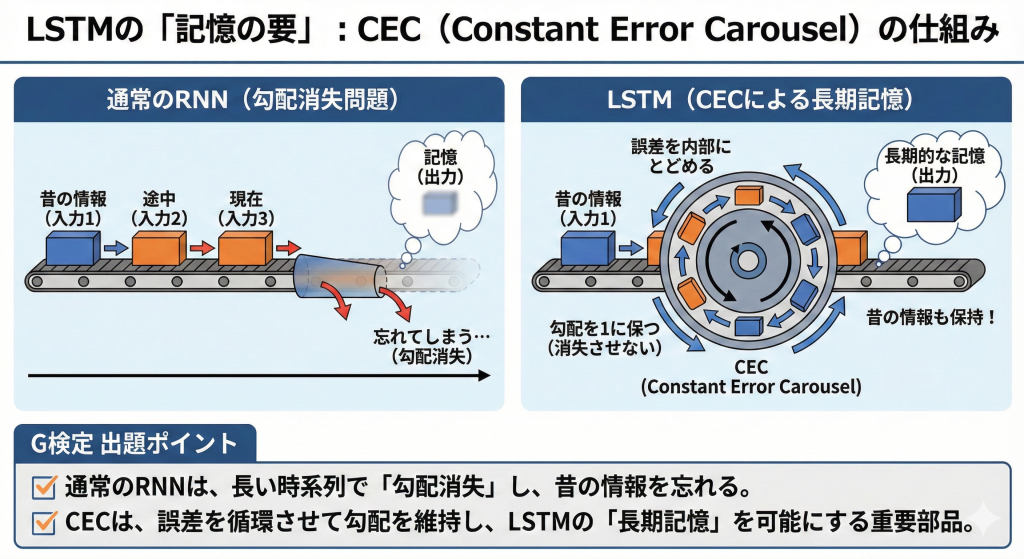
通常のRNNは、長い文章を学習すると昔の情報を忘れてしまう「勾配消失問題」がありました。
CECは、「誤差を内部にとどめ、勾配を1に保つ(消失させない)」仕組みを持ち、これにより長期的な記憶が可能になりました。
ELMo(Embeddings from Language Models)
「文脈化単語埋め込み」を実現したモデルです。
word2vecでは「bank(土手)」も「bank(銀行)」も同じベクトルでしたが、ELMoは双方向LSTM(BiLSTM)を使うことで、前後の文脈を見て、その都度異なるベクトルを生成できるようになりました。
BERT
2018年にGoogleが発表し、NLPの歴史を塗り替えたモデルです。Transformerの「Encoder」部分を使用しています。
学習の仕組み(事前学習)
BERTはラベルのない大量の文章を読み込み、以下の2つのタスクで「言葉の意味」を深く学習します。
- Masked Language Model (MLM):文章の一部を[MASK]で隠し、その穴埋め問題を解く。
- Next Sentence Prediction (NSP):ある文の次にくる文として、正しいかどうかを当てる。
これにより、文脈を「双方向」から深く理解できるのが特徴です。
GPT-n (GPT-2, GPT-3, GPT-4)
OpenAIが開発したモデル群です。BERTとは対照的に、Transformerの「Decoder」部分を使用しています。
学習の仕組み
「前の単語を見て、次の単語を予測する」というシンプルなタスクをひたすら繰り返します。
一方向(左から右)の予測しかできませんが、その分、流暢な文章を生成することに特化しています。
LLM関連の用語
- LLM(大規模言語モデル):数億〜数千億ものパラメータを持つ巨大な言語モデルの総称。BERTやGPTもこれに含まれます。
- ChatGPT:GPT-3.5やGPT-4をベースに、人間との「対話(チャット)」ができるように調整(ファインチューニング)されたモデルです。
- PaLM (Pathways Language Model):Googleが開発した超巨大LLM。5400億パラメータを持ち、論理推論やジョークの解説など高度な能力を示しました。
GLUE
「AIがどれくらい賢くなったか」を測るための、自然言語理解のベンチマーク(テスト問題集)です。
感情分析、含意関係認識など複数のタスクが含まれており、BERTやGPTなどの新しいモデルが出るたびに「GLUEスコアで人間を超えた」といった形で性能比較に使われます。
【まとめ】BERTとGPTの違い(G検定 必須知識)
非常によく似ているようで役割が違う2つのモデルを整理しました。ここだけは暗記しておきましょう。
| 項目 | BERT | GPTシリーズ |
|---|---|---|
| ベース構造 | Transformerの Encoder(エンコーダ) |
Transformerの Decoder(デコーダ) |
| 読む方向 | 双方向 (文章全体を同時に見る) |
一方向 (前から順番に見る) |
| 得意なタスク | 「理解・分類」 (文章分類、質問応答、固有表現抽出) |
「生成」 (文章作成、要約、翻訳) |
| 事前学習 | 穴埋め問題 (Masked LM) 次文予測 (NSP) |
次単語予測 (Language Modeling) |
