

単語の意味を捉える「分散表現」の登場
「ワンホットベクトル」には、大きな弱点がありました。それは、「単語同士の意味の近さが計算できない」ことです。
例えば、「王様」と「王子」は意味が近いですが、ワンホットベクトルではどちらも独立した「1」と「0」の羅列であり、計算上の関連性はゼロです。
この課題を解決し、「単語の意味や関係性を、ベクトル空間上の距離(近さ)で表現できるようになった」のが、この章で解説する技術群です。自然言語処理における革命的な進化と言えます。
単語埋め込み / 分散表現(Distributed Representation)
単語を、固定長の密なベクトル(例えば50〜300次元程度の実数値)に変換する技術の総称です。
- 局所表現(旧):次元数が膨大(語彙数と同じ)。中身はほとんど0。意味を含まない。
- 分散表現(新):次元数はコンパクト。中身は実数値が詰まっている。「意味が近い単語は、ベクトルも似ている」という特徴を持つ。
word2vec
2013年にGoogleの研究者(Mikolovら)によって提案された、分散表現を作るための画期的な手法です。ニューラルネットワークを使って、大量のテキストデータから単語のベクトルを学習します。
word2vecで学習したベクトルを使うと、単語の意味を計算することができます。最も有名な例が以下です。「王様」-「男」+「女」 ≒ 「女王」
「王様」という概念から「男」成分を引き、「女」成分を足すと、「女王」のベクトルに近い位置になる、というものです。
CBOW と Skip-gram
word2vecには、学習のさせ方に2つのモデル(アルゴリズム)があります。「何を入力して、何を予測させるか」の違いを整理して覚えましょう。
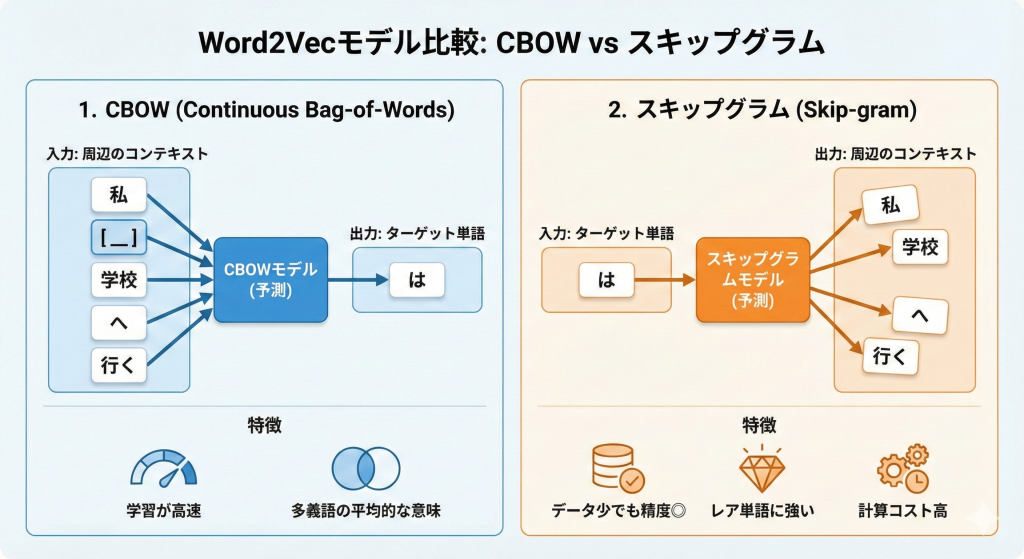
1. CBOW(Continuous Bag-of-Words)
「周辺」の単語から、「真ん中」の単語を予測するモデルです。
- 入力:周辺のコンテキスト(例:「私」「_」「学校」「へ」「行く」)
- 出力:ターゲット単語(例:「は」)
- 特徴:学習が高速。多義語の平均的な意味を捉えやすい。
2. スキップグラム(Skip-gram)
CBOWの逆です。「真ん中」の単語から、「周辺」の単語を予測するモデルです。
- 入力:ターゲット単語(例:「は」)
- 出力:周辺のコンテキスト(例:「私」「学校」「へ」「行く」)
- 特徴:学習データが少なくても精度が出やすい。レアな単語(低頻度語)の学習に強い。CBOWより計算コストは高い。
fastText
2016年にFacebook AI Research(現Meta)が開発した、word2vecの発展型モデルです。
word2vecの最大の弱点は、「学習時に登場しなかった単語(未知語)はベクトル化できない」ことでした。これを解決したのがfastTextです。
仕組み:サブワード(Subword)
単語をさらに細かい「文字の並び(サブワード)」に分解して学習します。
例えば「apple」という単語なら、そのまま覚えるのではなく、
<ap, app, ppl, ple, le>
といったパーツ(N-gram)の集合として扱います。
メリット
- 未知語に強い:「G-test」という単語を知らなくても、「G-」「test」というパーツを知っていれば、意味を推測してベクトルを作れる。
- スペルミスに強い:多少文字が間違っていても、共通するパーツが多ければ似た意味として認識できる。
