

画像分類 (Image Classification)
解説:AIによる「仕分け」作業
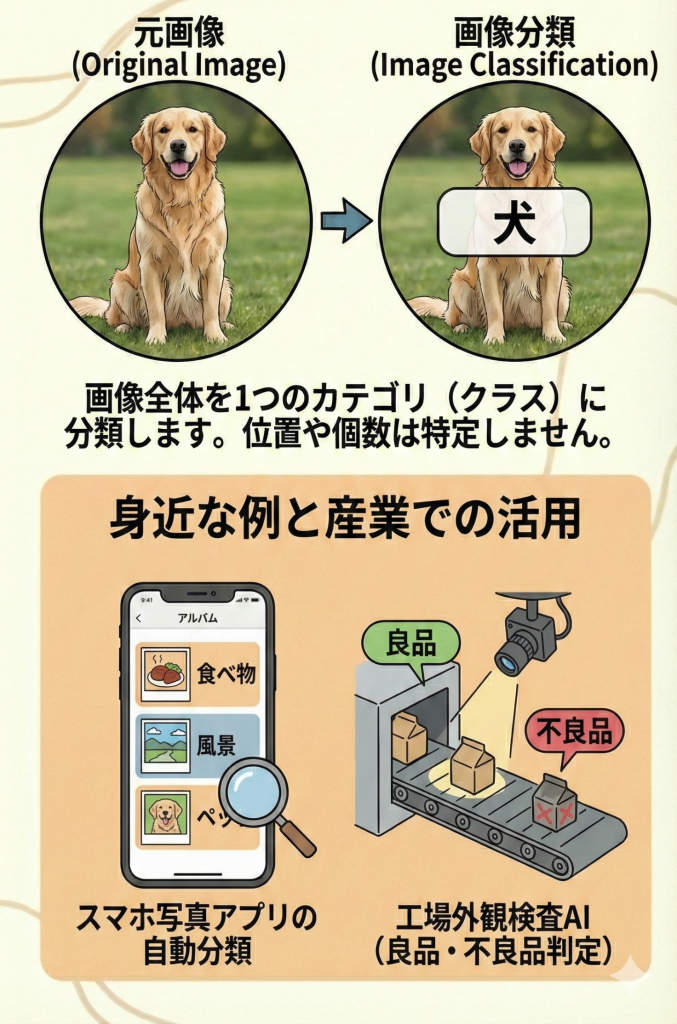
画像分類は、入力された画像全体を見て、「何が写っているか」を判断し、あらかじめ決められたカテゴリ(クラス)の中から1つのラベルを割り当てるタスクです。
人間が写真をパッと見て「これはラーメンだ」「これはカレーだ」と即答するのと同じ処理をAIに行わせます。画像認識の分野では最も基本的なタスクであり、ここから発展して「物体検出」などの高度な技術が生まれました。
📸 処理のイメージ
- 入力: 1枚の画像(例:犬の写真)
- 処理: 画像全体の特徴(形、色、模様など)をCNNで解析
- 出力: 「犬 (Dog)」というラベル(と確信度)
「できないこと」を知る
画像分類はあくまで「全体を見て一言で答える」タスクです。そのため、以下のことはできません。
- 位置の特定:「画像の右上に写っている」といった場所の情報(座標)は出力しません。
- 個数のカウント:「犬が3匹いる」といった数の判別は(基本的には)行いません。「犬」というクラスであることだけを答えます。
タスクの比較まとめ
| タスク名 | わかること(出力) | キーワード |
|---|---|---|
| 画像分類 (Classification) |
「何が」写っているか。 (What) |
クラスラベル (Class Label) |
| 物体検出 (Object Detection) |
「何が」「どこに」あるか。 (What + Where) |
バウンディングボックス (囲い枠) |
G検定対策
出題ポイント
- 定義:画像全体に対して、単一(または複数)のラベルを付与するタスク。
- 歴史:「ILSVRC(ImageNet)」という画像分類コンペティションを通じて、AlexNetやResNetなどの有名なCNNモデルが進化してきた。
- 限界:「どこにあるか(Localization)」は扱わない。
ひっかけ対策
- 「画像分類では物体の位置を特定するためにバウンディングボックスを出力する」→ × 誤り。
それは「物体検出」の説明です。画像分類は位置を特定しません。 - 「複数の物体が写っている場合、それぞれの位置を特定できる」→ × 誤り。
画像分類では、画像全体に対して「これはパーティの画像」のようにラベルをつけることはできますが、個々の物体の位置までは分かりません。
