

パノプティックセグメンテーション (Panoptic Segmentation)
解説:画像認識の「完全体」
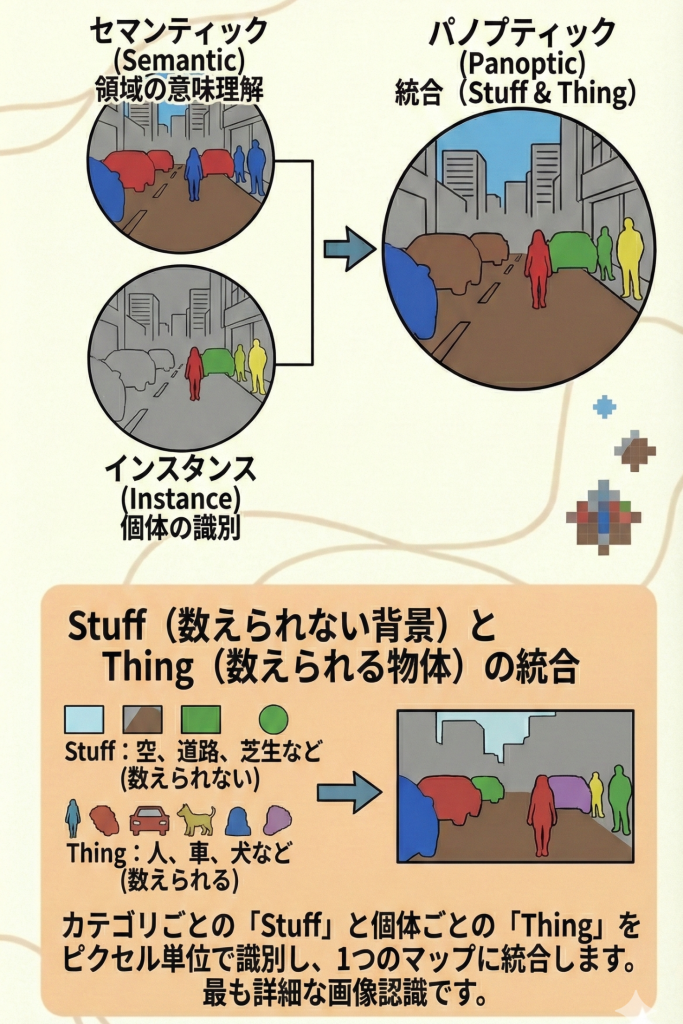
パノプティックセグメンテーションは、「セマンティックセグメンテーション(背景の理解)」と「インスタンスセグメンテーション(個体の識別)」を同時に行う、画像認識の中で最も詳細で欲張りなタスクです。
これまでのタスクには、それぞれ「苦手なこと」がありました。
- セマンティック:背景(空や道路)は得意だが、人ごみの中で「個体」を区別できない。
- インスタンス:人や車(個体)は得意だが、背景(空や道路)は無視してしまう。
この両方の弱点を克服し、「画像の隅から隅まで、全てのピクセルに意味を持たせて、かつ個体も区別する」のがパノプティックセグメンテーションです。
重要キーワード:「Stuff」と「Thing」
この技術を理解する上で、対象を2つの性質に分ける考え方が重要です。
🌳 Stuff(スタッフ):数えられないもの(背景)
- 空、道路、芝生、壁、海など。
- 形が定まっておらず、「1つ、2つ」と数えることが難しい領域。
- 扱い:セマンティックセグメンテーションで処理(同じクラスなら全部同じ色)。
🚗 Thing(シング):数えられるもの(物体)
- 人、車、犬、コップ、信号機など。
- 明確な形があり、「個体」としてカウントできる物体。
- 扱い:インスタンスセグメンテーションで処理(個体ごとに別の色)。
3つのセグメンテーション比較まとめ
| タスク名 | 背景 (Stuff) | 物体 (Thing) | 目的 |
|---|---|---|---|
| セマンティック | 塗る | 塗る (個体識別×) |
シーン全体の意味理解 |
| インスタンス | 無視 | 塗る (個体識別◎) |
特定の物体の検出・計測 |
| パノプティック | 塗る | 塗る (個体識別◎) |
完全なシーン理解 (自動運転など) |
G検定対策
出題ポイント
- 定義:セマンティックとインスタンスを統合したタスクであり、画面内の全てのピクセルにラベルを割り当てる。
- 用語:数えられない背景を「Stuff」、数えられる物体を「Thing」と定義して区別する。
- 応用:自動運転において、「道路(Stuff)」を認識しながら、飛び出してくる「歩行者(Thing)」を個別に追跡するために必須の技術。
ひっかけ対策
- 「パノプティックは背景を無視する」→ × 誤り。
背景も認識します。背景を無視するのは「インスタンスセグメンテーション」です。 - 「Stuffも個体識別する」→ × 誤り。
空や道路(Stuff)には個体の概念がないため、ひとまとまりとして扱います。個体識別するのはThingだけです。
