

物体検出モデルの進化を極める:「精度」と「速度」の戦いの歴史
「画像の中に何が(分類)、どこにあるか(位置特定)」を同時に行う技術が「物体検出(Object Detection)」です。
この分野の歴史は、いかにして「高い精度」を維持したまま、実用的な「処理速度」を実現するかという戦いの歴史でもあります。
G検定では、この「2段階型(精度重視)」から「1段階型(速度重視)」へのパラダイムシフトと、それぞれの代表的なモデルの仕組みが頻出ポイントとなります。
【この記事でわかること】
- R-CNN系(2段階型)の進化と高速化の工夫
- YOLO・SSD(1段階型)が登場した背景と仕組み
- 小物体検出を可能にしたFPNの役割
- G検定で問われる「キーワード」と「モデルの分類」
1. Fast R-CNN:R-CNNの弱点を克服(2段階型)
物体検出の先駆けである「R-CNN」は画期的でしたが、処理が非常に遅い(1枚に数十秒)という課題がありました。これを劇的に高速化したのがFast R-CNNです。
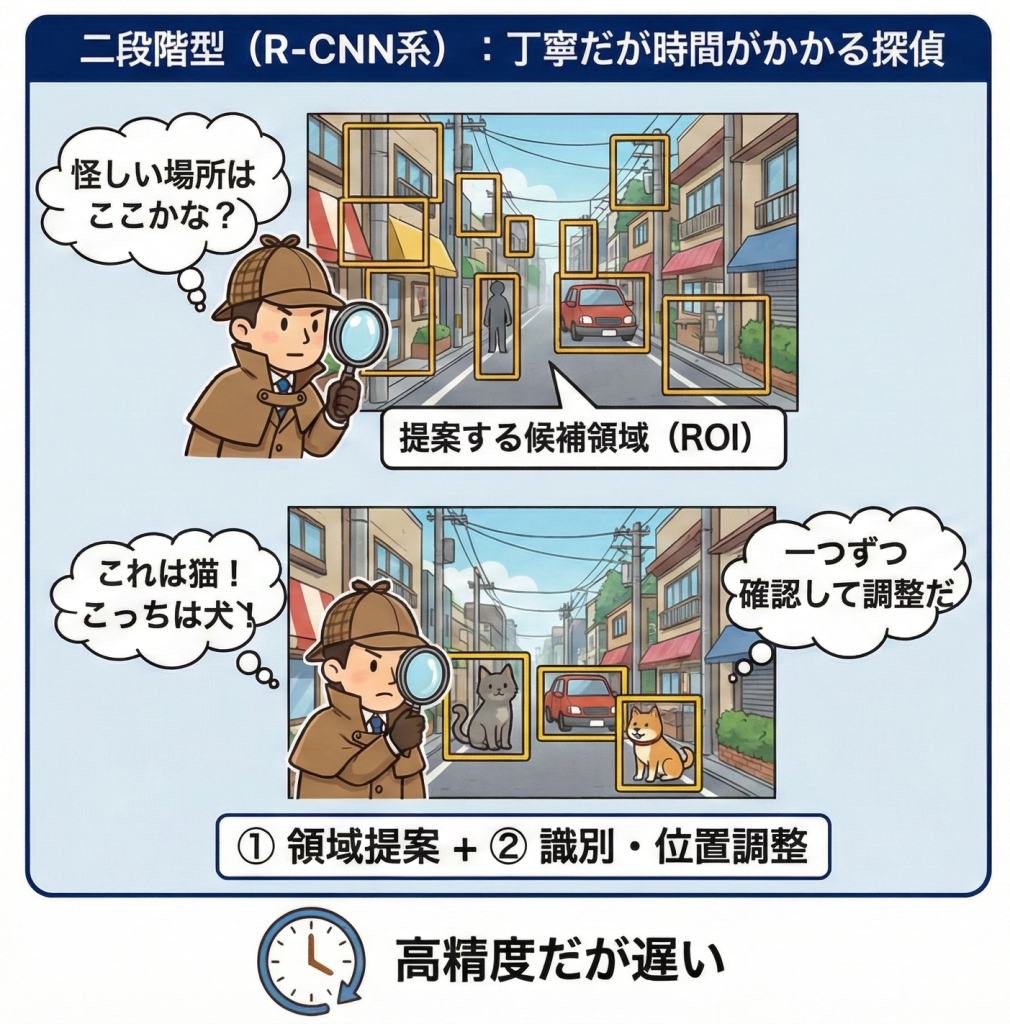
最大の特徴は、CNNによる特徴抽出を「画像全体に対して1回だけ」行う点です。
- 主な特徴:
- RoI Pooling(Region of Interest Pooling):CNNで抽出した特徴マップから、候補領域(RoI)に該当する部分だけを切り出して固定長に変換する技術。
- マルチタスク損失:分類(クラス予測)と回帰(位置ズレの修正)を1つのネットワークで同時に学習。
- R-CNNに比べて学習・推論ともに大幅に高速化したが、領域提案(どこに物体がありそうか)の処理はまだ外部のアルゴリズム(Selective Search)に依存していた。
2. Faster R-CNN:完全なエンドツーエンド学習へ(2段階型)
Fast R-CNNでボトルネックとなっていた「領域提案」のプロセスまでもニューラルネットワーク(CNN)の中に組み込んだモデルです。これにより、入力から出力までを一貫して学習できる「End-to-End(エンドツーエンド)」を実現しました。
- 主な特徴:
- RPN(Region Proposal Network):物体がありそうな領域(候補)を自動で提案する専用のネットワークを導入。
- アンカーボックス(Anchor Box):様々なサイズやアスペクト比(縦横比)の枠をあらかじめ用意しておき、効率的に探索する仕組み。
- 2段階型(Two-stage)検出器の完成形として、現在でも高精度モデルのベースラインとなっている。
3. SSD(Single Shot MultiBox Detector):精度と速度の両立(1段階型)
Faster R-CNNは高精度ですが、リアルタイム処理にはまだ速度が足りませんでした。そこで登場したのが、領域提案と分類を同時に行う「1段階型(One-stage)」のモデルです。

SSDは、処理速度を保ちつつ、YOLO(後述)の弱点だった精度の低さを克服しました。
- 主な特徴:
- マルチスケール特徴マップ:CNNの異なる深さ(解像度)の層から特徴を取り出し、大きな物体も小さな物体も検出できるようにした。
- デフォルトボックス(Default Box):Faster R-CNNのアンカーボックスと同様の仕組みを採用し、様々な形状の物体に対応。
- 「Single Shot」の名の通り、1回の処理ですべてを完了させるため高速。
4. YOLO(You Only Look Once):圧倒的なリアルタイム性(1段階型)
「画像を見るのは1回だけ(You Only Look Once)」という名の通り、人間がパッと見て瞬時に状況を把握するように、圧倒的な速度を実現したモデルです。
物体検出を「分類問題」ではなく、座標を予測する「回帰問題」として再定義した点が革新的でした。
- 主な特徴:
- グリッド分割:画像をグリッド(格子)状に分割し、各グリッドごとに「バウンディングボックス」と「クラス確率」を直接予測する。
- 背景の誤検出(False Positive)が少ない。
- 初期のYOLO(v1)は、グリッド内に複数の物体がある場合や、小さな物体の検出が苦手だった(後にYOLO v2, v3…と進化し改善)。
5. FPN(Feature Pyramid Network):小さな物体を見逃さない(拡張構造)
これは独立した検出モデルではなく、上記のモデル(Faster R-CNNやSSDなど)に組み込んで性能を底上げする「ネットワーク構造」です。
ディープラーニングは層が深くなるほど「意味」は理解しますが、「位置情報」が曖昧になり、小さな物体が見えなくなる問題がありました。
- 主な特徴:
- 特徴ピラミッド:深い層(強い意味情報)と浅い層(正確な位置情報)を結合して利用する構造。
- 大小さまざまなサイズの物体を、高い精度で検出可能にする。
- 現在では、RetinaNetやYOLOの新しいバージョンなど、多くのモデルのバックボーンとして採用されている。
G検定向けポイントまとめ
物体検出モデルは「2段階型(精度寄り)」か「1段階型(速度寄り)」かの区別が最重要です。
| モデル名 | タイプ | キーワード(試験対策) | 特徴を一言で |
|---|---|---|---|
| Fast R-CNN | 2段階型 | RoI Pooling, マルチタスク損失 | R-CNNの高速化(CNNは1回) |
| Faster R-CNN | 2段階型 | RPN, アンカーボックス | 領域提案もCNN化(End-to-End) |
| SSD | 1段階型 | マルチスケール特徴マップ | 多層の特徴を使い精度と速度を両立 |
| YOLO | 1段階型 | グリッド分割, 回帰問題 | グリッドごとの予測で爆速処理 |
| FPN | 拡張構造 | 特徴ピラミッド | 小物体検出に強い構造 |
