

積層オートエンコーダ(Stacked Autoencoder)
解説:ディープラーニングの「夜明け」を作った技術
積層オートエンコーダは、2006年にジェフリー・ヒントンやヨシュア・ベンジオらによって提案された、オートエンコーダを何層にも積み重ねてディープ(深層)にする手法です。
当時、層を深くすると学習がうまく進まない(勾配消失などの)問題がありましたが、このモデルは「1層ずつ丁寧に教育していく」という画期的なアプローチでその壁を突破しました。これが現在のディープラーニングブームの火付け役となりました。
学習の2ステップ(ここが最重要!)
いきなり全体を学習させるのではなく、以下の2段階の手順を踏むのが最大の特徴です。
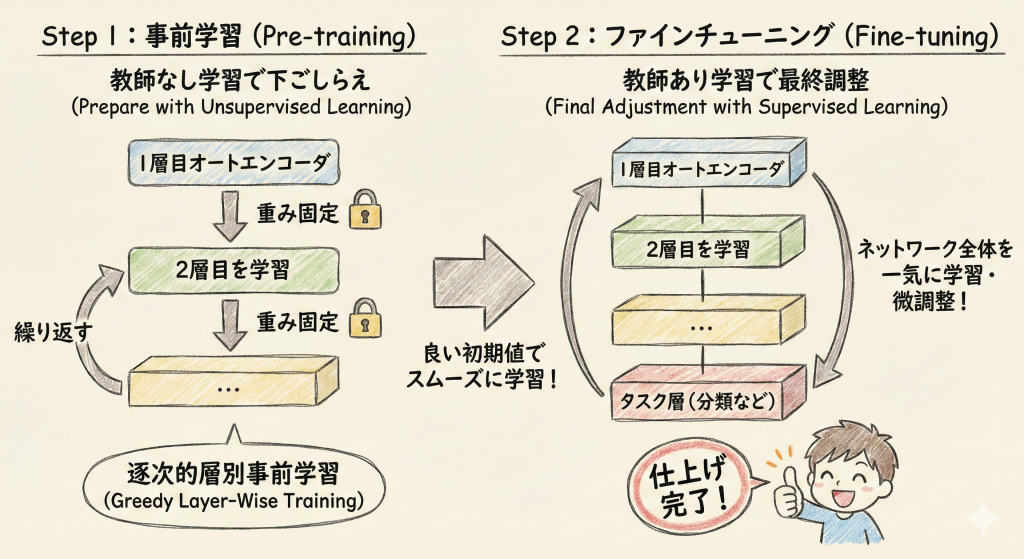
Step 1:事前学習(Pre-training)
「教師なし学習」で下ごしらえ
「教師なし学習」で下ごしらえ
- 1層目のオートエンコーダだけを学習させて、重みを固定します。
- 次に、その出力を入力として2層目を学習させます。これを繰り返します。
- これを専門用語で「逐次的層別事前学習(Greedy Layer-Wise Training)」と呼びます。
Step 2:ファインチューニング(Fine-tuning)
「教師あり学習」で最終調整
「教師あり学習」で最終調整
- 積み上げた層を全部つなげて、最後に本来解かせたいタスク(分類など)の層をくっつけます。
- ネットワーク全体を一気に学習させ、微調整(仕上げ)を行います。
- Step 1で「良い重みの初期値」が見つかっているため、スムーズに学習が進みます。
G検定対策
出題ポイント
- 歴史的意義:深層学習の学習が困難だった時代に、「事前学習 → ファインチューニング」という手法で多層化を可能にした。
- 学習手法:1層ずつ順番に学習させる「逐次的層別事前学習」を行う。
- 現在:ReLUやBatch Normalizationなどの技術が登場したため、現在ではこの手法を使わなくても深層学習が可能になり、あまり使われなくなっている。(※歴史問題として出題される)
ひっかけ対策
- × 最初から全層を同時に学習させる
(解説)それは通常のディープラーニングです。積層オートエンコーダは「1層ずつ」がポイントです。 - × 教師あり学習のみを用いる
(解説)前半の事前学習は「教師なし学習(オートエンコーダ)」で行い、後半の仕上げで教師あり学習を使います。
