

位置エンコーディング (Positional Encoding)
解説:バラバラの原稿に「ページ番号」を振る
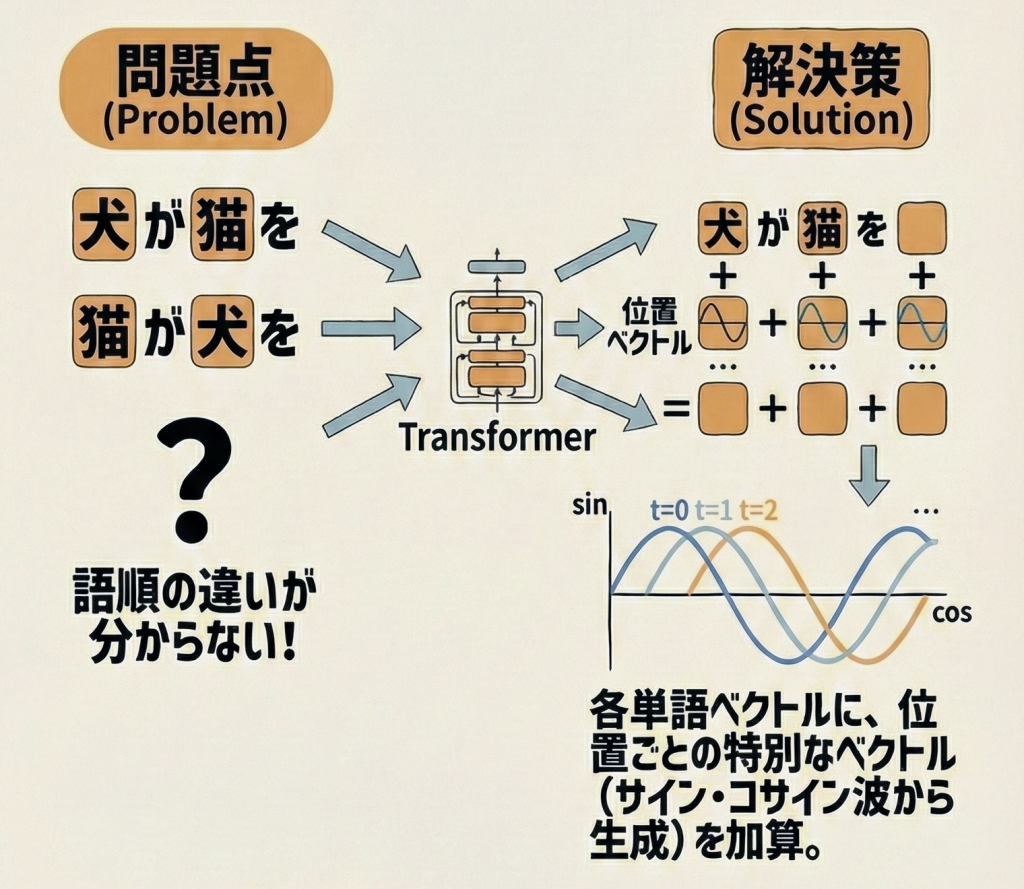
位置エンコーディング(Positional Encoding)は、Transformerに「単語の語順(位置情報)」を教えるための仕組みです。
TransformerのSelf-Attentionは、文章を頭から読むのではなく、全単語を「せーの」で一気に並列処理します。これは計算が爆速になる反面、「単語の順番がわからなくなる」という致命的な弱点を生みます。
🐈 語順がないとどうなる?以下の2つの文は、単語の成分だけ見れば全く同じです。
- 「猫 が 犬 を 追いかける」
- 「犬 が 猫 を 追いかける」
RNNは順番に読むので区別できましたが、Transformerはこのままだと両方を「猫・犬・追いかける」という同じ袋に入った集合(Bag of Words)として処理してしまいます。
そこで、各単語データに「これは1番目」「これは3番目」というタグ(位置情報)を埋め込むことで、順番を区別できるようにしました。
足し算で情報を合成する
具体的には、単語の意味を表すベクトル(単語埋め込み)に、位置を表すベクトル(位置エンコーディング)を「足し算(Add)」します。
位置ベクトルには、単純な整数(1, 2, 3…)ではなく、サイン(sin)やコサイン(cos)などの周期関数から作られた特殊な波のパターンが使われます。これにより、どんなに長い文章でも、独特な「位置の指紋」を付与することができます。
| モデル | 順序の認識方法 | 特徴 |
|---|---|---|
| RNN | 構造的に認識。 (順番に入力するから自然とわかる) |
位置エンコーディングは不要。 ただし並列処理ができない。 |
| Transformer | 位置エンコーディングで認識。 (入力データに順序情報を付加する) |
並列処理のメリットを維持したまま、文脈(語順)を理解できる。 |
G検定対策
出題ポイント
- 目的:並列処理によって失われる「単語の順序情報」を補うために導入された。
- 方法:単語埋め込みベクトル(Word Embedding)に対し、位置情報を表すベクトルを「加算(要素ごとの足し算)」する。
- 生成:一般的に「正弦波(sin/cos関数)」を用いて、位置ごとに異なるパターンを生成する。(※学習によって位置情報を獲得させる手法もある)
ひっかけ対策
- × RNNで最も重要な技術である
(解説)RNNは構造上、最初から順序を理解できます。これは「Transformer」や「CNNで自然言語を扱う場合」に必要な技術です。 - × 位置情報と単語情報を『結合(Concat)』する
(解説)基本的にはベクトルの次元を変えずに「加算(Add)」します。結合すると次元数が増えて計算コストが上がるためです。
