

教師強制 (Teacher Forcing)
解説:間違った道を突き進むのを防ぐ「軌道修正」
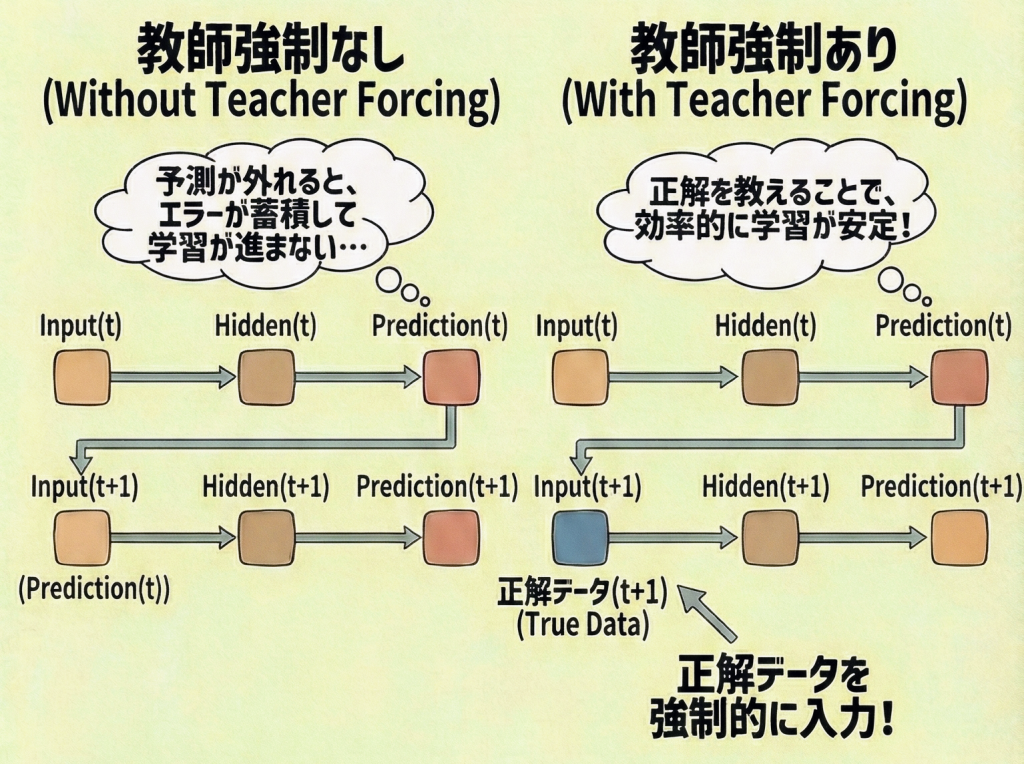
教師強制(Teacher Forcing)とは、RNNなどの「時系列データを順番に生成するモデル(翻訳や文章生成など)」の学習において、モデル自身が予測した値ではなく、「本当の正解データ」を次の入力として強制的に与える手法です。
なぜ「強制」が必要なのか?(誤差の蓄積)
文章生成などのタスクでは、前の単語をヒントにして次の単語を予測します。
学習を始めたばかりのAIは当然間違えますが、もし「自分の間違った予測」を次のヒントとして使ってしまうと、どうなるでしょうか。
| 手法 | 学習時の動き(例:「私は猫です」を生成したい) | 結果 |
|---|---|---|
| 教師強制なし (自分の予測を使う) |
1語目:「私は」と予測。 2語目:「私は」をヒントに「犬」と誤予測。 3語目:「犬」をヒントに「だワン」と誤予測。 |
一度間違えると、雪だるま式にエラーが蓄積し、学習が完全に崩壊(迷子)してしまいます。 |
| 教師強制あり (正解を与える) |
1語目:「私は」と予測。 2語目:「私は」をヒントに「犬」と誤予測。 3語目:(先生が介入)「違うよ、2語目の正解は『猫』だよ。『猫』に続く言葉は?」→「です」と予測。 |
間違えても直前の「本当の正解」をヒントとして与えるため、エラーの連鎖を防ぎ、学習が素早く安定します。 |
副作用:「露出バイアス」問題
教師強制は学習を劇的に安定させますが、弱点もあります。それは「本番環境(テスト時)には、正解を教えてくれる先生がいない」ということです。
練習では常に「正しい直前の言葉」をもらえていたのに、本番では「自分自身の(不確実な)予測」を頼りに次を予測しなければなりません。この「練習(常に正解が与えられる)と本番(自分の予測を使う)の環境の違い」によって精度が落ちてしまう問題を露出バイアス(Exposure Bias)と呼びます。
G検定対策
出題ポイント
- 対象:RNNなどの系列生成モデル(自然言語処理や音声認識など)で用いられる学習テクニック。
- 仕組み:学習時に、前ステップの「モデルの予測値」ではなく、「正解データ(Ground Truth)」を次ステップの入力として与える。
- メリット:学習序盤のエラーの蓄積(連鎖)を防ぎ、学習を早期に安定させる。
- デメリット:推論(テスト)時との環境のギャップが生じる「露出バイアス(Exposure Bias)」が課題となる。
よくあるひっかけ問題
- × 教師強制は、テスト(推論)時にも正解データを与えて精度を上げる手法である
(解説)誤りです。テスト時にはそもそも「正解データ」が存在しないため、自分自身の予測を入力するしかありません。教師強制が使えるのは「学習時」のみです。 - × 教師強制を行うと、露出バイアスが解消される
(解説)逆です。教師強制を行うこと「によって」露出バイアスという新たな問題が発生します。これを緩和するために、学習が進むにつれて少しずつ教師強制の割合を減らす「Scheduled Sampling」などの対策手法が存在します。
