

最適化手法(Momentum / AdaGrad / RMSprop / Adam)
解説
SGD(確率的勾配降下法)の「ジグザグに進む」「学習率の調整が難しい」といった弱点を克服するために、様々な最適化手法が提案されてきました。
- Momentum(モーメンタム):
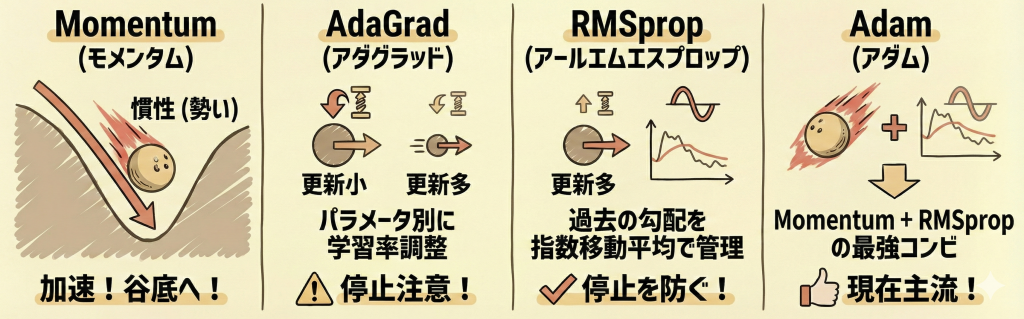
勾配に「慣性(勢い)」を加える手法。坂道を転がるボールのように、谷底に向かって加速し、小さなデコボコ(局所最適解)を勢いで乗り越えやすくします。 - AdaGrad(アダグラッド):
パラメータごとに学習率を個別に調整します。「あまり更新されていない重み(レアな特徴)」は大きく動かし、「頻繁に更新される重み」は小さく動かします。
※ただし、学習が進むと学習率が限りなくゼロに近づき、途中で学習が停止してしまう欠点があります。 - RMSprop:
AdaGradの「学習が止まる」欠点を修正した手法。過去の勾配を「指数移動平均」で管理し、古い情報を忘れながら学習率を調整します。 - Adam(アダム):
「Momentum(慣性)」と「RMSprop(学習率の自動調整)」のいいとこ取りをした手法。現在、ディープラーニングで最も標準的に使われています。
G検定対策
出題ポイント
- Momentum:「前回の更新量」を利用した「慣性(勢い)」項を持つ。
- AdaGrad:パラメータごとに学習率を変える(Adaptive)が、学習が進むと学習率が0になり停止する欠点がある。
- Adam:MomentumとRMSpropを組み合わせた現在最も普及している手法。
ひっかけ対策
- × AdaGradは学習が進むほど学習率が大きくなる
(解説)誤りです。分母に勾配の二乗和が蓄積されるため、学習率は単調に小さくなります。 - × Adamはハイパーパラメータを全く調整する必要がない
(解説)誤りです。デフォルト設定で優秀なことが多いですが、学習率などは調整が必要な場合があります。
