

トピックモデル (Topic Model)
解説
トピックモデルとは、大量の文書データから、その裏側に潜んでいる「トピック(話題・テーマ)」を統計的に推定する、教師なし学習の手法です。
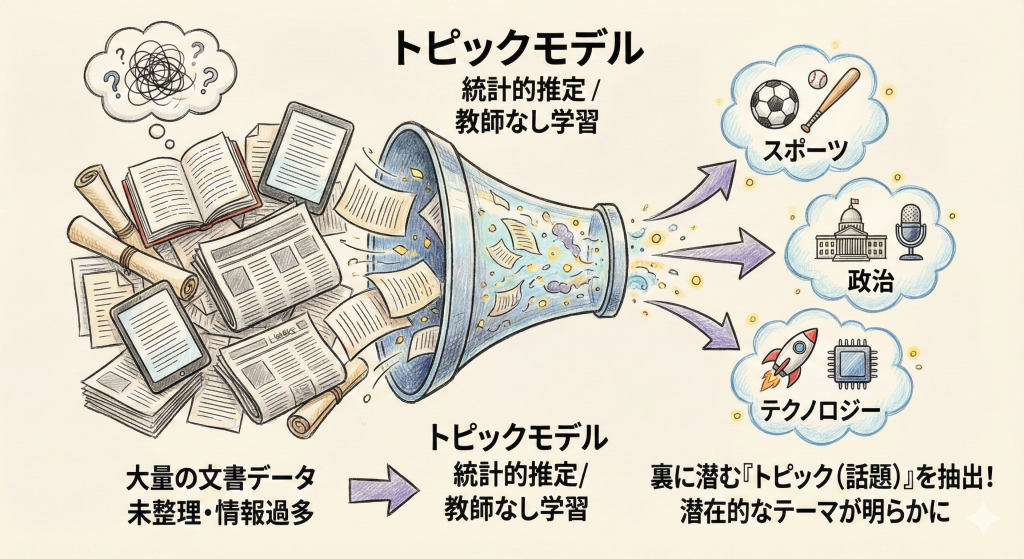
「1つの文書には、複数のトピックが混ざっている」
トピックモデルの最大の特徴は、文書を「スポーツ」「政治」のように1つのジャンルに分類するのではなく、「このニュース記事は、スポーツ要素が70%、経済要素が30%で構成されている」というように、複数のトピックの「混合(確率分布)」として捉える点です。
代表的手法:LDA(潜在的ディリクレ配分法)
トピックモデルの中で最も有名で、G検定で頻出のアルゴリズムがLDA(Latent Dirichlet Allocation)です。
LDAは、「文書はトピックのサイコロを振って決まり、トピックは単語のサイコロを振って決まる」という確率的な生成プロセス(ディリクレ分布)を仮定して、逆算的にトピックを推定します。
活用例
- ニュース記事の解析:大量の記事を「政治」「スポーツ」「芸能」などのトピックに自動でグルーピングする。
- 購買分析:レシートのデータから、「健康志向」「節約志向」といった顧客の潜在的な関心を推定する。
G検定対策
出題ポイント
- 定義:文書集合から潜在的なトピック(意味的なまとまり)を抽出する「教師なし学習」。
- アルゴリズム:代表例として「LDA(潜在的ディリクレ配分法)」がある。
- 仕組み:「文書ごとのトピック分布」と「トピックごとの単語分布」を推定する。
- 関連手法:LSI(潜在的意味インデックス)やpLSA(確率的潜在意味解析)の発展形として位置づけられることが多い。
よくあるひっかけ問題
- × トピックモデルは、文書に正解ラベル(カテゴリ)を与えて学習させる手法である
(解説)正解ラベルを使わない「教師なし学習(クラスタリングの一種)」です。人間が「これはスポーツ記事だ」と教えなくても、自動的に「スポーツっぽい単語の集まり」を見つけ出します。 - × 1つの文書は、必ず1つのトピックにのみ属する
(解説)トピックモデル(特にLDA)では、1つの文書は「複数のトピックの混合」であると考えます(例:このブログ記事はAIが6割、数学が4割、など)。
