

k-means 法(k-means clustering)
1. 解説
k-means 法(k平均法)は、教師なし学習における「非階層的クラスタリング」の代表的なアルゴリズムです。
データを「あらかじめ決めた k 個のグループ(クラスター)」に分けることを目的とします。ビッグデータに対しても計算が比較的速いため、マーケティングの顧客分類や画像減色処理など、実務でも広く使われています。
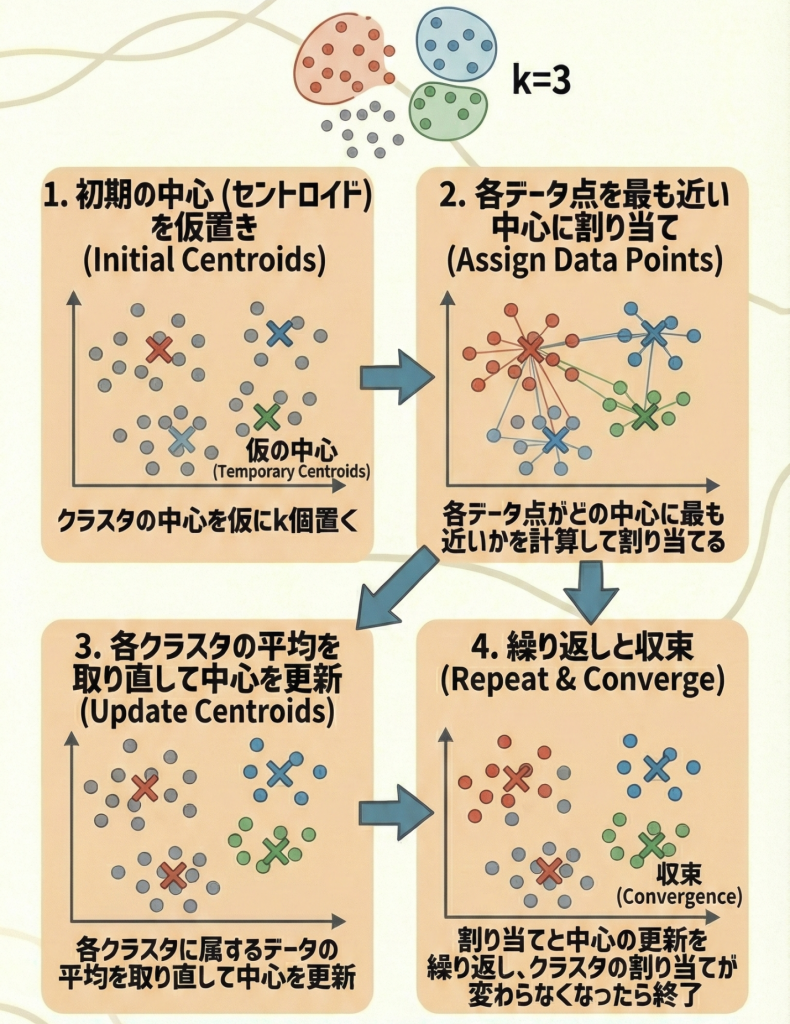
アルゴリズムの4ステップ
k-meansは、以下の手順を繰り返すことで自動的にグループ分けを行います。
- 初期化:データの中からランダムに k個 の点を選び、それを仮の中心(セントロイド)とする。
- 割り当て:全てのデータを、最も距離が近い中心のグループに割り当てる。
- 更新:各グループに割り当てられたデータの「平均(重心)」を計算し、新しい中心とする。
- 反復:中心の位置が変わらなくなる(収束する)まで、2と3を繰り返す。
k-means法の弱点と対策
非常に便利な手法ですが、万能ではありません。G検定ではこの「弱点」への対策が問われます。
| 弱点・課題 | 解説 | 対策・関連用語 |
|---|---|---|
| kの値を決める必要がある | 「いくつのグループに分けるか」を人間が最初に設定しなければならない。 | エルボー法 (グラフの折れ曲がり具合を見て最適なkを探す手法) |
| 初期値に依存する | 最初にランダムに選んだ中心の位置によって、結果が悪くなる(局所解に陥る)ことがある。 | k-means++ (最初の中心同士をできるだけ離れた場所に配置する工夫をした手法) |
| 複雑な形に弱い | 距離で判断するため、球状(ボール状)のグループしか綺麗に分けられない。三日月型などは苦手。 | スペクトラルクラスタリングなど別の手法を検討する。 |
2. G検定対策
出題ポイント
- 重心の更新:「各クラスタの平均をとって中心を移動させる」というプロセスを理解しているか。
- 非階層的:階層的クラスタリング(デンドログラムを作るもの)とは異なり、階層構造を持たない。
- k-means++:「初期値をできるだけ離して選ぶ」ことでk-meansの安定性を高めた改良版。
ひっかけ対策・注意点
- 【最重要】k-近傍法(k-NN)との混同:
名前が似ていますが、全く別の手法です。- k-means法(k平均法):教師なし学習(クラスタリング)。グループ分けに使う。
- k-近傍法(k-NN):教師あり学習(分類)。多数決で新しいデータのクラスを決める。
- kは自動では決まらない:
「データから自動的に最適なクラスタ数kを決定する」という選択肢は間違いです(kは人間が決めるハイパーパラメータです)。
