

ロジスティック回帰(Logistic Regression)
1. 解説
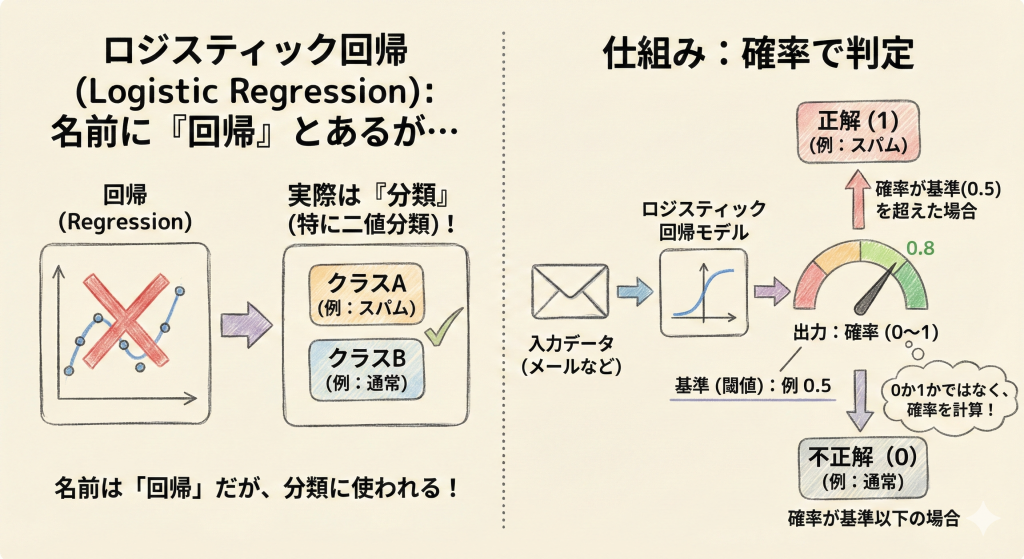
ロジスティック回帰は、名前に「回帰」とついていますが、実際には「分類問題」(特に二値分類)に使われる代表的なアルゴリズムです。ここがG検定で最も狙われやすいポイントです。
この手法は、あるデータが特定のクラスに属するかどうかを「0か1か」で直接出力するのではなく、「そのクラスに属する確率(0〜1の範囲)」として計算するのが特徴です。その確率が設定した基準(閾値)を超えた場合に「正解(1)」と判定します。
判定までの3ステップ
ロジスティック回帰が答えを出すまでの流れを整理すると以下のようになります。
| ステップ | 処理内容 | キーワード |
|---|---|---|
| 1. 線形結合 | 入力データに重みを掛けて足し合わせる。 (この時点では値は -∞ 〜 +∞ ) |
線形モデル |
| 2. 確率変換 | ステップ1の値を0〜1の範囲に押し込める。 「確率70%」のような数値になる。 |
シグモイド関数 |
| 3. クラス判定 | 確率が基準(閾値)を超えているかで判定。 例:50%以上なら「合格」、未満なら「不合格」 |
閾値(Threshold) |
重要キーワード:シグモイド関数
ロジスティック回帰の心臓部となる関数です。どんな入力値が来ても、滑らかなS字カーブを描いて必ず 0.0 〜 1.0 の間に変換する性質を持っています。これにより出力を「確率」として扱うことが可能になります。
2. G検定対策
出題ポイント
- 目的:「二値分類(Yes/No)」などの分類タスクに使われる。
- 活性化関数:「シグモイド関数」を用いて確率を出力する。
- 性質:単純パーセプトロンと同様に「線形分離可能」な問題(直線で引いて分けられる問題)が得意。
