

AdaBoost (Adaptive Boosting)
解説
AdaBoost(エイダブースト)は、1995年にYoav FreundとRobert Schapireによって提案された、ブースティング(アンサンブル学習)の代表的なアルゴリズムです。
「間違えた問題」を重点的に復習する
AdaBoostの仕組みは、受験勉強に例えると分かりやすくなります。
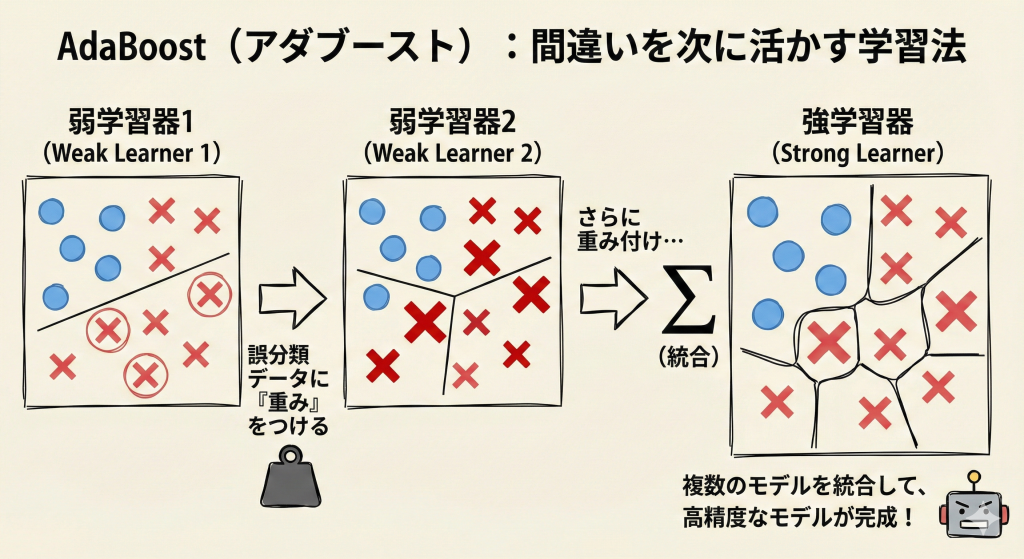
- まず、すべての練習問題(データ)を解きます。
- 間違えた問題に「付箋(重み)」を貼ります。
- 次は、付箋の貼られた(=間違えやすかった)問題を重点的に解くような新しい学習器を作ります。
- これを繰り返し、最後にすべての学習器の意見を統合します。
弱学習器:「決定株(Decision Stump)」
AdaBoostでは、非常に単純なモデル(弱学習器)を積み重ねます。一般的には、深さが1しかない(1回しか分岐しない)決定木である「決定株(Decision Stump)」が用いられます。
最終決定:重み付き多数決
最終的な予測を行う際、すべての学習器が対等ではありません。「学習段階で成績が良かったモデル」の発言力を大きく、「成績が悪かったモデル」の発言力を小さくして多数決を行います(重み付き多数決)。
G検定対策
出題ポイント
- メカニズム:「誤分類されたデータの重み(Weight)を更新する」ことで精度を上げる。
- 弱学習器:一般的に「決定株(Decision Stump)」と呼ばれる、深さ1の決定木が使われる。
- 学習方法:前のモデルの結果を受けて次を作るため、「直列(逐次的)処理」となる(並列化は困難)。
よくあるひっかけ問題
- × AdaBoostは、前のモデルの「残差(誤差)」を予測するように学習する
(解説)これは「勾配ブースティング(GBDT)」の説明です。AdaBoostは「重み」を調整し、GBDTは「残差」を学習します。この違いは超頻出です。 - × 決定木の深さを深くすることで、個々のモデルの精度を高める
(解説)AdaBoostでは、あえて「弱いモデル(決定株)」を使います。深い木を使うと過学習してしまうためです。
