

ランダムフォレスト (Random Forest)
解説
ランダムフォレストは、複数の「決定木」を組み合わせる(アンサンブル学習)ことで、単体の決定木よりも高い精度と汎化性能を実現する機械学習アルゴリズムです。
最強のバギング手法
ランダムフォレストは、アンサンブル学習の中でも「バギング(Bagging)」を進化させた手法です。以下の2つの「ランダム(無作為)」な要素を取り入れることで、多様性のある森(決定木の集まり)を作ります。
- データのランダム性:ブートストラップサンプリングにより、学習データをランダムに抽出する(ここは通常のバギングと同じ)。
- 特徴量のランダム性:決定木の分岐を作る際、すべての特徴量から選ぶのではなく、ランダムに選ばれた一部の特徴量の中から最適なものを選ぶ。
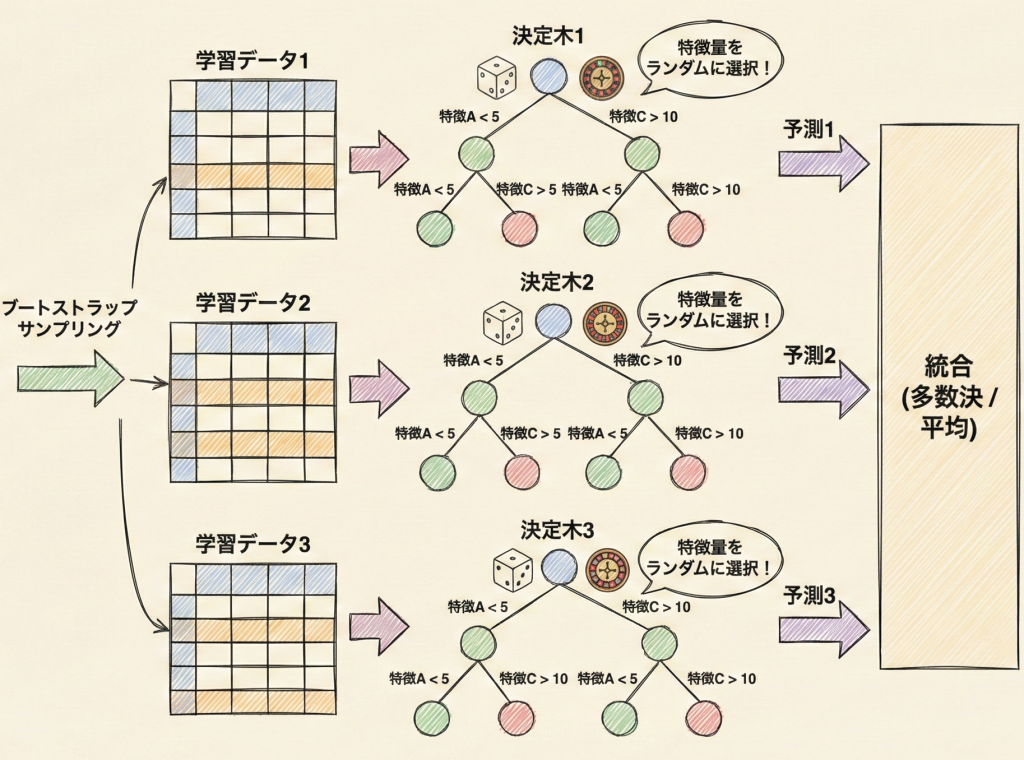
この2点目の工夫により、似通った木ができるのを防ぎ(木の相関を下げ)、過学習のリスクを劇的に減らすことに成功しています。
メリット:並列化と変数重要度
- 高速学習:それぞれの木は独立して学習できるため、並列処理が可能で計算が速い。
- 変数重要度(Feature Importance):「どの特徴量が予測に役立ったか」を数値化して算出できるため、分析の解釈に役立つ。
G検定対策
出題ポイント
- アルゴリズム:「バギング」+「特徴量のランダム選択」。
- 処理の特性:木同士が独立しているため、「並列処理」が可能(ここが勾配ブースティング等の直列処理との最大の違い)。
- 機能:学習結果から「変数重要度(Feature Importance)」を算出できる。
- ハイパーパラメータ:「決定木の数(n_estimators)」や「木の深さ(max_depth)」、「分岐に使う特徴量数(max_features)」などが問われる。
よくあるひっかけ問題
- × ランダムフォレストは、前の木の学習結果を利用して次の木を学習する(直列処理)
(解説)それは「ブースティング(GBDTなど)」の説明です。ランダムフォレストはそれぞれの木が独立している「並列処理」です。 - × 決定木の分岐において、常にすべての特徴量の中から最適な分割を選択する
(解説)ランダムフォレストは「ランダムに選ばれた一部の特徴量(サブセット)」の中から選択します。これにより木の多様性を確保しています。
