

サポートベクターマシン (SVM)
解説
サポートベクターマシン(SVM)とは、教師あり学習(主に分類タスク)で用いられる強力なアルゴリズムです。ディープラーニングが流行する前は、「最強の分類器」として広く使われていました。
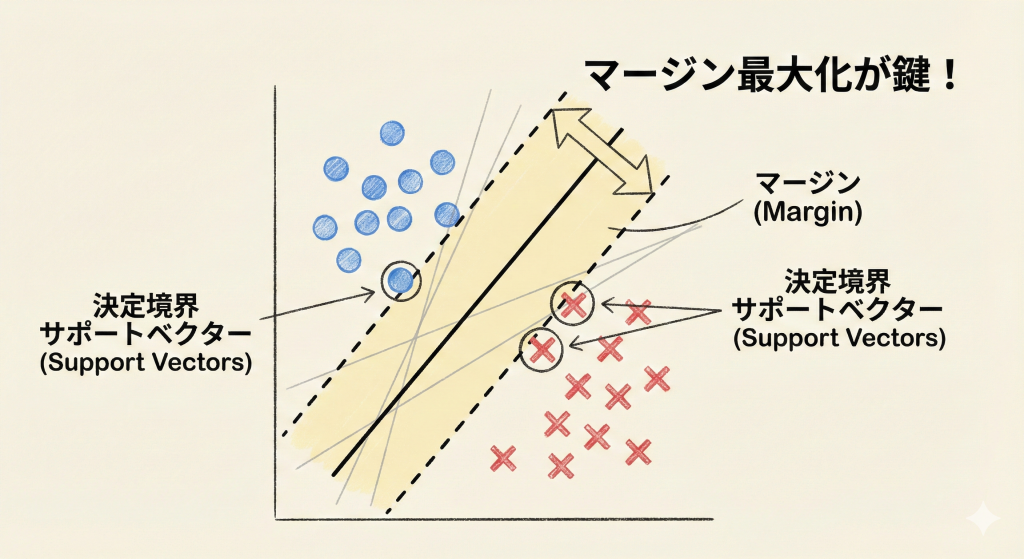
「マージン最大化」が最大の鍵
SVMの最大の特徴は、データを分ける境界線(決定境界)を引く際に、「マージン(境界線とデータ点との距離)を最大化する」ことです。
- サポートベクター:境界線に最も近いデータ点のこと。この点だけが境界線の決定に関与します。
- マージン:サポートベクターと決定境界との距離。これが広いほど、未知のデータに対する識別性能(汎化性能)が高くなります。
カーネル法による非線形分離
本来、SVMは直線でしかデータを分けられませんが、「カーネル法(カーネルトリック)」を使うことで、曲がった境界線(非線形分離)も引けるようになります。
これは、データを高次元空間(2次元→3次元など)に写像することで、高次元上で「平面」で切れるようにするテクニックです。
ハードマージンとソフトマージン
- ハードマージン:誤分類を一切許さない厳格な設定。ノイズ(外れ値)に弱く、過学習しやすい。
- ソフトマージン:多少の誤分類やマージン内への侵入を許容する設定。ノイズに強く、汎化性能が高い。G検定ではこの「許容する」という概念が重要です。
G検定対策
出題ポイント
- 基本概念:「マージン最大化」により汎化性能を高める。
- 用語:境界線を決めるデータを「サポートベクター」と呼ぶ。
- テクニック:「カーネル法」で非線形分離に対応。「ソフトマージン」で誤分類を許容(スラック変数という概念も関わる)。
- 計算コスト:データ数が増えると計算量が大幅に増えるため、大規模データには不向きな側面がある。
よくあるひっかけ問題
- × SVMは、すべてのデータ点を使って境界線を決定する
(解説)違います。境界線の決定に関与するのは、境界付近にある一部のデータ(サポートベクター)だけです。 - × SVMは線形分離しかできない
(解説)「カーネル法(RBFカーネルなど)」を使えば、複雑な非線形分離も可能です。
