

過学習(オーバーフィッティング)
解説:勉強しすぎて応用がきかない状態
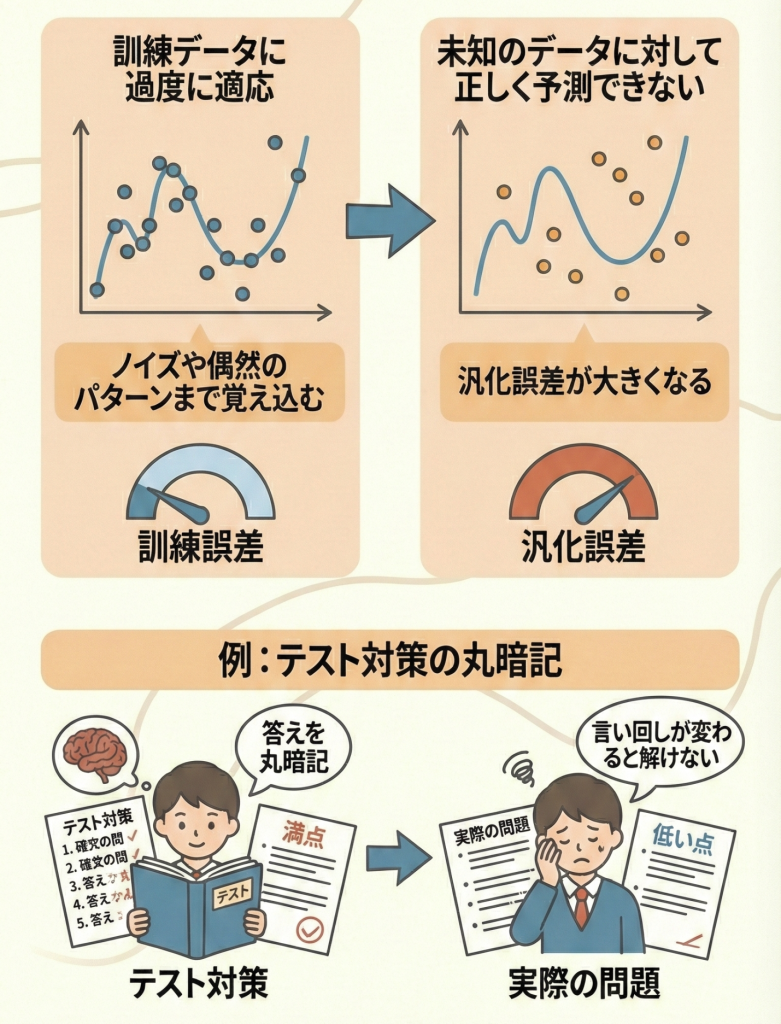
過学習(Overfitting)とは、AIモデルが手元の「訓練データ」に適応しすぎてしまい、未知のデータ(テストデータ)に対して正しく予測できなくなる状態のことです。
訓練データに含まれる細かいノイズや、たまたま発生した偏りまで「重要なルール」だと勘違いして暗記してしまうことで発生します。この状態になると、「訓練誤差(練習問題のミス)」は限りなく0に近づくのに、「汎化誤差(本番のミス)」は逆に大きくなってしまいます。
わかりやすい例:「丸暗記の落とし穴」
テスト勉強で、問題集の答えを「ア、ウ、イ…」と記号で丸暗記してしまった学生を想像してください。
この学生は、その問題集(訓練データ)なら100点が取れますが、実際の試験(未知のデータ)で数字や言い回しが少し変わると、全く解けなくなってしまいます。
これが過学習の状態です。本来目指すべきは、公式や解き方を理解する「汎化(Generalization)」の状態です。
過学習の「原因」と「対策」
G検定では、このペアを覚えているかが問われます。
| 主な原因 | 代表的な対策 |
|---|---|
| 学習データが少なすぎる (偏った特徴を覚えやすい) |
|
| モデルが複雑すぎる (表現力が高すぎて、ノイズまで再現してしまう) |
G検定対策
出題ポイント
- 定義の理解:「訓練誤差は小さい(良い)」のに「汎化誤差が大きい(悪い)」というギャップが生じている状態を指す。
- 対策手法の名前:「正則化」「ドロップアウト」「アーリーストッピング(早期終了)」などの用語が、過学習対策として正しいか選ばせる問題が頻出。
- 検証:ホールドアウト検証や交差検証を行い、過学習していないかチェックする。
ひっかけ対策
- 「未学習(学習不足)」との混同:訓練誤差も汎化誤差も両方大きい(そもそも学習できていない)状態は「未学習(Underfitting)」です。過学習とは区別しましょう。
- 「精度100%」の罠:訓練データに対する精度が100%に近い場合、優秀なモデルである可能性よりも、過学習を疑う必要があります。
