

音声処理の基礎:AIは「音」をどう聴いているのか?
SiriやAlexaなどの音声アシスタント、Zoomの自動字幕生成など、私たちの身の回りには「音声AI」があふれています。
しかし、コンピュータにとって「音」は単なる空気の振動です。これをどのようにデータ化し、AIに理解させているのでしょうか?
この記事では、G検定でも頻出の「音声処理」の仕組み、特徴量の作り方、そして代表的なモデルまでを初心者向けに解説します。
1. 音声データの基本:アナログからデジタルへ
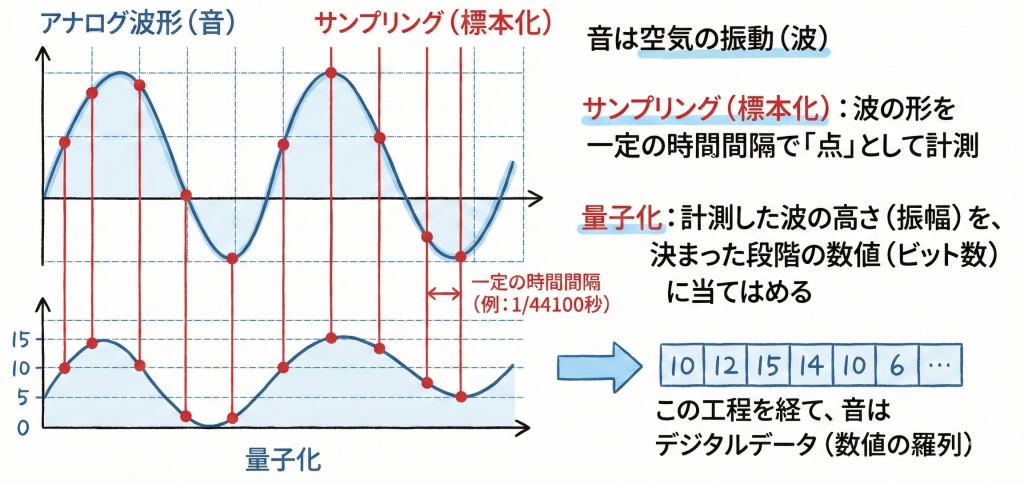
音は空気の振動(波)であり、そのままではコンピュータで扱えません。マイクで拾った連続的な波形(アナログ信号)を、コンピュータが扱える「デジタル信号」に変換する処理を「A-D変換」と呼びます。
パルス符号変調(PCM:Pulse Code Modulation)
A-D変換の最も代表的な方式です。CD音質(44.1kHz、16bit)などの高音質オーディオ記録で用いられる「非圧縮」の方式で、以下の3ステップで行われます。
- サンプリング(標本化):波の形を一定の時間間隔で測定すること。
※1秒間の測定回数を「サンプリング周波数」と言います(例:CDは44.1kHz)。 - 量子化:測定した波の高さ(振幅)を、決まった段階の数値(ビット数)に丸めること。
- 符号化:その数値を2進数(0と1のビット列)に変換すること。
MP3などの圧縮音源とは異なり、元の音に忠実なデジタル表現が可能ですが、データ容量は大きくなります。
2. 音の最小単位とタスクの種類
音声処理を学ぶ上で、「音をどのくらいの粒度で扱うか」を知っておく必要があります。
音素と音韻
- 音素(Phoneme):言語を構成する「最小の音の単位」です。
日本語の「おはよう」であれば、「o / h / a / y / o / u」のように分解されます。 - 音韻:文中の意味のまとまりや発音のタイミングを表す構造的な単位で、話し方やニュアンスに関する概念です。
主な音声処理タスク
| タスク名 | 概要と具体例 |
|---|---|
| 音声認識 (ASR) |
音声をテキストに変換する処理。 (例:スマートスピーカー、自動字幕、音声入力) |
| 音声合成 (TTS) |
テキストから人間のような音声を生成する処理。 (例:ナビ音声、アシスタントの回答) |
| 音響イベント検出 | 「ガラスが割れた音」「足音」など、何の音かを特定する処理。 (例:防犯カメラの異常検知) |
3. 音声の特徴表現(G検定の最重要ポイント)
生の波形データは情報量が多すぎるため、AIが理解しやすい「特徴量」に変換します。
(1) フーリエ変換 (Fourier Transform)
信号(時系列データ)を「周波数成分」に分解する処理です。これにより、「どの高さの音がどれくらい含まれているか」がわかります。
- FFT(高速フーリエ変換):コンピュータで高速に計算するアルゴリズム。音声だけでなく、株価の変動分析や脳波解析などにも使われます。
- STFT(短時間フーリエ変換):音を短い区間で区切りながらFFTを行う手法です。
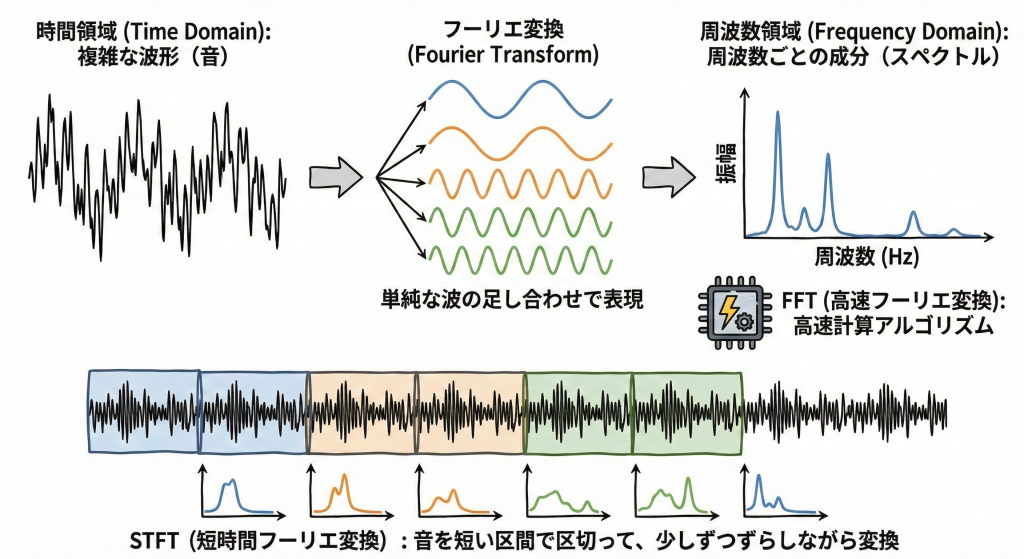
(2) スペクトログラムと「音色の特徴」
STFTの結果を可視化したものを「スペクトログラム」と呼びます(横軸:時間、縦軸:周波数)。ここからさらに、声の質や個人性を表す重要な特徴を読み取ることができます。
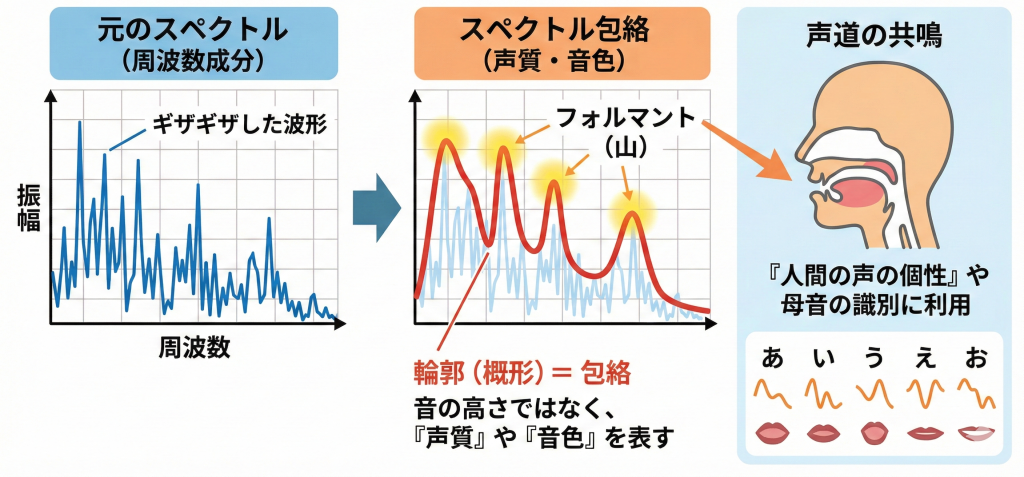
- スペクトル包絡:周波数成分のギザギザした波形の「輪郭(概形)」のこと。音の高さではなく、「声質」や「音色」の違いを表します。
- フォルマント(フォルマント周波数):スペクトル包絡に見られる「山(盛り上がっている部分)」の周波数。声道の共鳴によって生じ、「人間の声の個性」や母音(あいうえお)の識別に利用されます
(3) メル周波数ケプストラム係数 (MFCC)
スペクトログラム(スペクトル包絡)を、さらに「人間の耳の聞こえ方(メル尺度)」に合わせて加工した特徴量です。音声認識の精度を劇的に向上させた立役者です。
4. 代表的な音声処理モデル
歴史的な手法から最新のDeep Learningモデルまで、試験に出るポイントを押さえましょう。
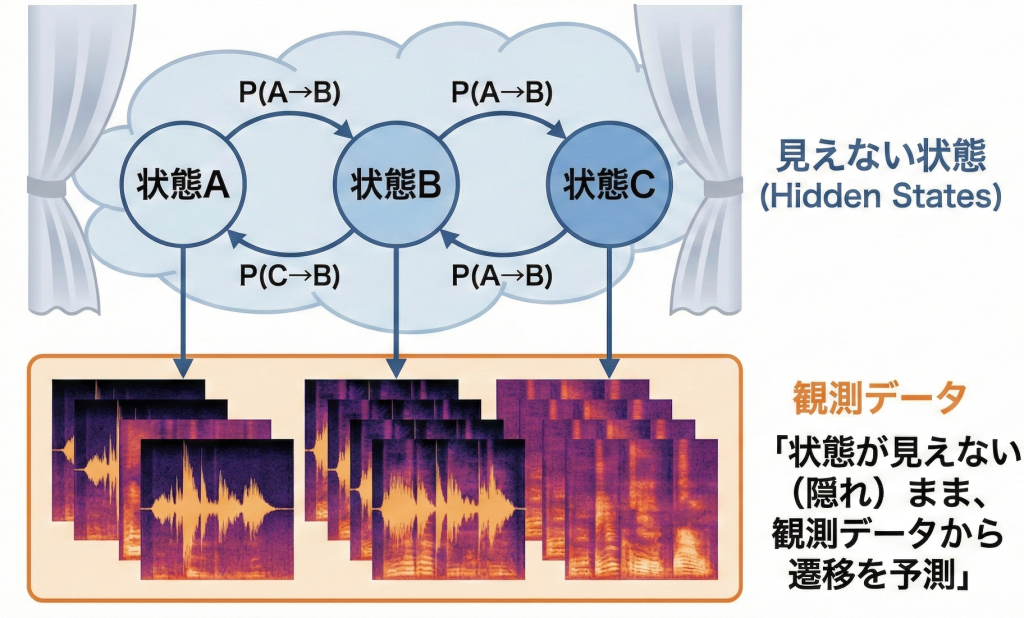
HMM(隠れマルコフモデル)
ディープラーニング以前に主流だった時系列モデルです。
「状態が見えない(隠れ)まま、観測データからその遷移を予測する」という確率的な仕組みで、音声の時間的な変化を扱っていました。
HMMは、以下の2つの確率を組み合わせてモデル化します。
- 遷移確率(Transition Probability):ある状態から次の状態へ移る確率。(例:「お」と言った後に「は」と言う確率)
- 出力確率(Emission Probability):ある状態から、特定のデータが観測される確率。(例:「あ」という発音記号から、実際にマイクが「あ〜」という波形を拾う確率)
現在はRNNやTransformerに置き換えられつつあります。
WaveNet
2016年にDeepMind社が開発した、革命的な音声合成モデルです。
- 仕組み:「PixelCNN」という画像生成モデルを応用し、畳み込みニューラルネットワーク(CNN)を用いて音声波形そのものを1点ずつ生成します。
- パラメトリックTTSとの違い:従来の「パラメトリックTTS(音声波形とテキストをパラメータで記述して合成する手法)」に比べ、大量のデータを学習でき、人間と区別がつかないほど自然な音声を生成可能にしました。
CTC(Connectionist Temporal Classification)
RNNなどで音声認識を行う際の「損失関数」です。入力(音声)と出力(テキスト)の長さが違うという問題を、「空白(blank)」クラスを導入することで解決しました。
まとめ
音声処理は、「PCMなどのA-D変換」から始まり、「FFTやフォルマント抽出」などの前処理を経て、「WaveNetやTransformer」などのモデルで処理されます。
特に「スペクトル包絡=音色」「フォルマント=声の個性」といった結びつきはG検定でよく問われるので、しっかり覚えておきましょう。


📚 より詳細を学びたい方へ

