

勾配ブースティング (Gradient Boosting)
解説
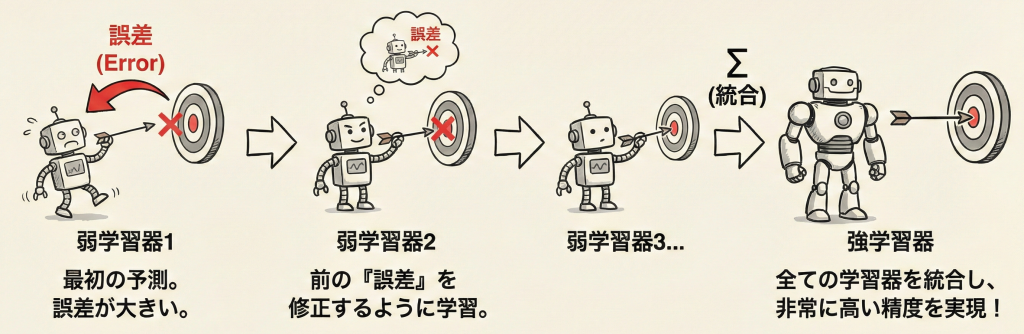
勾配ブースティング(Gradient Boosting)とは、複数の「弱い学習器(主に浅い決定木)」を順番に作成し、前のモデルの失敗(誤差)を次のモデルが修正していくことで、非常に精度の高いモデルを作り上げるアンサンブル学習の手法です。
「残差(誤差)」を予測するバケツリレー
勾配ブースティングの最大の特徴は、「前のモデルが出した誤差(残差)」そのものを、次のモデルの予測対象にする点です。
ゴルフのパットに例えると分かりやすいでしょう。
- 1打目(モデル1):カップ(正解)を狙ったが、5mショートした(誤差 = 5m)。
- 2打目(モデル2):カップではなく、残りの「5m」を狙って打つ。少しズレて1m残った。
- 3打目(モデル3):残りの「1m」を狙って打つ。
このように、正解そのものではなく「残りの距離(誤差)」を次々と埋めていくことで、最終的にカップイン(正解)に限りなく近づけるアプローチです。
AdaBoostとの違い
同じブースティング手法である「AdaBoost」との違いは、G検定の頻出ポイントです。
- AdaBoost:間違えたデータの「重み」を増やして、重要度を上げる。
- 勾配ブースティング:間違えた分の「残差(値)」を直接予測しにいく。
最強の進化系:XGBoost, LightGBM
勾配ブースティングをさらに高速化・高精度化したものが、XGBoost、LightGBM、CatBoostです。これらは現在のAI開発の現場やデータ分析コンペで最も使われているアルゴリズムです。
G検定対策
出題ポイント
- メカニズム:損失関数の値を最小化するために、「勾配降下法」の考え方を用いて、前のモデルの「残差(Residual)」を学習していく。
- 学習方法:前の結果が必要なため、「直列(逐次的)処理」となる(ランダムフォレストのような並列処理は基本できない)。
- 弱学習器:一般的に「決定木(回帰木)」が使われる。
よくあるひっかけ問題
- × 勾配ブースティングは、誤分類したデータの重みを更新する手法である
(解説)それは「AdaBoost」の説明です。勾配ブースティングは「残差」を学習します。 - × バギングと同様に、並列処理によって高速に学習できる
(解説)ブースティングはバケツリレー形式(直列)なので、並列化による高速化は構造的に難しいです(LightGBMなどは特徴量の探索などを工夫して高速化しています)。


📚 より詳細を学びたい方へ

