

ルールベース機械翻訳(RBMT)
解説
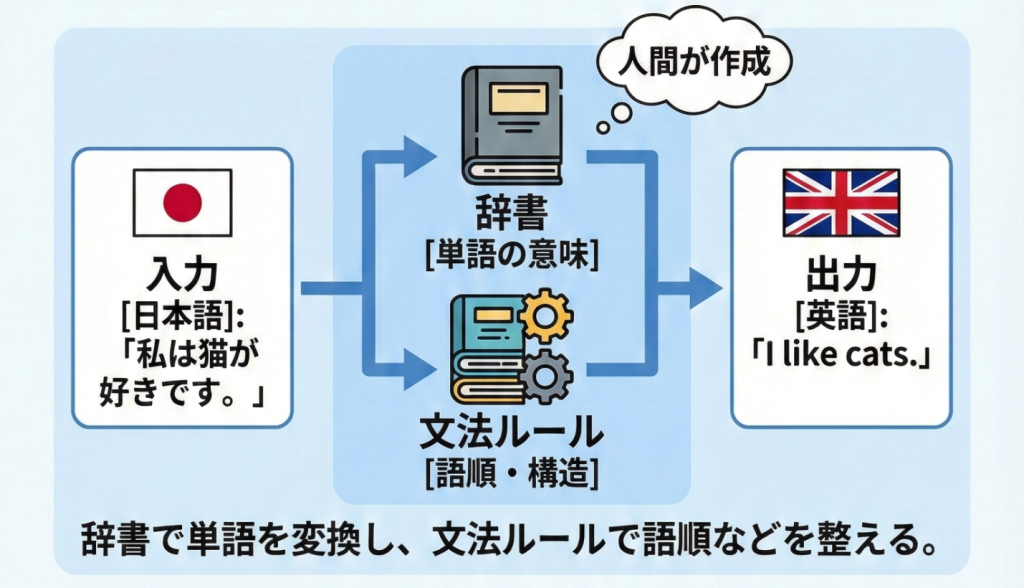
ルールベース機械翻訳(RBMT:Rule-Based Machine Translation)とは、1950年代から1980年代にかけて主流だった、最も古典的な機械翻訳の手法です。人間の言語学者が作成した「辞書」と「文法ルール」をコンピュータに登録し、それを厳密に適用することで翻訳を行います。
翻訳の仕組み(解析・変換・生成)
RBMTは、主に以下の3段階のプロセスで翻訳を行います。
- 解析(Analysis):原文を単語に分解し、品詞や構文解析(S+V+Oなど)を行う。
- 変換(Transfer):解析した構造を、ターゲット言語の構文構造に変換する(例:英語のSVOを日本語のSOVに並べ替える)。
- 生成(Generation):変換された構造に基づいて、ターゲット言語の単語を生成して出力する。
メリットと致命的な限界
「文法的に正しい定型文」であれば正確に翻訳できるため、マニュアル翻訳などでは一定の成果を上げました。しかし、「自然言語は例外だらけである」という壁に直面しました。スラング、省略、文脈による意味の変化など、無限にある例外ルールをすべて人間が手書きで修正・追加する必要があり、開発・保守コストが膨大すぎて限界を迎えました。
G検定対策
出題ポイント
- キーワード:「辞書」「文法規則」「人手によるルール記述」。
- 歴史的変遷:最も古い手法であり、「ルールベース」→「統計的(SMT)」→「ニューラル(NMT)」の流れの起点となる。
- 欠点:ルールの記述コストが高いこと、曖昧性(Ambiguity)への対応が苦手なこと。
よくあるひっかけ問題
- × ルールベース機械翻訳は、ディープラーニングを用いてルールを自動生成する
(解説)「ルールを自動生成」するのは機械学習以降のアプローチです。RBMTは人間が手動でルールを作ります。 - × 現在の翻訳エンジン(Google翻訳など)はルールベースが主流である
(解説)現在はニューラル機械翻訳(NMT)が主流です。ただし、一部の専門用語の固定など、補助的にルールベースが使われることはあります。
